
GraphQL، یک زبان کوئری برای APIها و یک runtime برای اجرای آن کوئریها با دادههای موجود شما است. GraphQL، توضیحات کامل و قابل فهم از دادههای موجود در API شما را فراهم میکند و همچنین به کلاینتها این قدرت را میدهد که دقیقاً همان چیزی که نیاز دارند (و نه چیزی بیشتر) را درخواست نمایند.
این برنامه، APIهای تکامل یافته را با مرور زمان ساده کرده و ابزارهای قدرتمند توسعه دهنده را ایجاد مینماید. در این مقاله، مزایا و معایب GraphQL بررسی شده است تا بتوانید خودتان تصمیم بگیرید که آیا مناسب پروژه شما هست یا خیر.
واکشی دقیق اطلاعات
ارائه قابلیت واکشی دقیق داده از طریق زبان GraphQL اصلیترین ویژگی این زبان است. با استفاده از GraphQL، شما میتوانید یک کوئری برای API خود ارسال کنید و دقیقاً همان چیزی را که نیاز دارید (و نه چیزی بیشتر یا کمتر) دریافت نمایید. این کار واقعاً خیلی ساده است. اگر این ویژگی را با ماهیت بصری متداول REST مقایسه کنید، خواهید فهمید که این یک پیشرفت بزرگی در نحوه انجام کارها است.
GraphQL، بسته به نیاز برنامه کلاینت، با انتخاب در مورد داده، مقدار داده مورد نیاز برای انتقال را به حداقل میرساند. بنابراین، یک کلاینت موبایل میتواند اطلاعات کمتری را واکشی کند؛ زیرا ممکن است در یک صفحه کوچک در مقایسه با صفحه بزرگتر برای برنامه وب، نیازی به بسیاری از آن اطلاعات نباشد.
بنابراین به جای چندین نقطه پایانی (endpoint) که ساختارهای داده ثابت را برمیگرداند، یک سرور GraphQL تنها یک نقطه انتهایی را نشان میدهد و دقیقاً دادههای درخواست شده کلاینت را پاسخ میدهد.
شرایطی را در نظر بگیرید که در آن میخواهید یک نقطه پایانی API را فراخوانی کنید که دارای دو منبع است: هنرمندان و آهنگهای آنها.
برای اینکه بتوانید یک هنرمند خاص یا آهنگهای موسیقی او درخواست نمایید، ساختار API مشابه زیر را باید داشته باشید:
METHOD /api/:resource:/:id:
با الگوی سنتی REST، اگر بخواهیم لیستی از هر هنرمند را با استفاده از API ارائه شده جستجو کنیم، باید به صورت زیر، درخواست GET را به نقطه پایانی منبع ریشه ارائه دهیم:
GET /api/artists
اما اگر بخواهیم برای یک هنرمند بصورت جداگانه از لیست هنرمندان درخواست بدهیم، چه میکنیم؟ بدین منظور باید ID منبع را به صورت زیر به نقطه پایانی ضمیمه نماییم:
GET /api/artists/1
در واقع، برای بدست آوردن دادههای مورد نیاز، باید دو نقطه پایانی متفاوت را فراخوانی کنیم. اما با GraphQL، هر درخواست میتواند بدون نیاز به فراخوانی بیش از یک نقطه پایانی انجام شده و دادههای درخواست شده در کوئری به کلاینت برگردانده شود. فرض کنید میخواهیم آهنگهای یک هنرمند را به همراه مدت زمان هر آهنگ بدست آوریم. بدین منظور با استفاده از GraphQL، کوئری مشابه زیر را خواهیم داشت:
GET /api?query={ artists(id:"1") { track, duration } }
این کوئری به API دستور میدهد تا هنرمندی را با شناسه 1 جستجو کرده و سپس آهنگ او و مدت زمان آن را برگرداند که این دقیقاً همان چیزی است که ما میخواستیم (نه بیشتر و نه کمتر). از همین نقطه پایانی میتوان برای انجام اقدامات درون API نیز استفاده کرد.
این مطلب نیز ممکن است برای شما مفید باشد: پایگاه داده چیست؟ SQL چیست؟
یک درخواست، چند منبع
یکی دیگر از ویژگیهای مفید GraphQL این است که واکشی تمام دادههای مورد نیاز را با یک درخواست ساده میکند. ساختار سرورهای GraphQL امکان واکشی چندتایی دادهها را فراهم مینماید؛ زیرا تنها به یک نقطه پایانی واحد نیاز دارد.
شرایطی را در نظر بگیرید که در آن یک کاربر بخواهد جزئیات یک هنرمند خاص، مثلاً نام، شناسه، آهنگها و غیره را درخواست کند. با الگوی بصری REST سنتی، این حداقل به دو درخواست از دو نقطه انتهایی /artists و /tracks نیاز دارد. با این حال، با GraphQL میتوان تمام دادههای مورد نیاز را در یک کوئری تعریف کرد، همانطور که در زیر نشان داده شده است:
// the query request
artists(id: "1") {
id
name
avatarUrl
tracks(limit: 2) {
name
urlSlug
}
}
در اینجا، ما یک درخواست GraphQL واحد برای درخواست به چندین منبع (artists و tracks) تعریف کردهایم. این کوئری، کل (و تنها) منابع درخواستی را به صورت زیر برمیگرداند:
// the query result
{
"data": {
"artists": {
"id": "1",
"name": "Michael Jackson",
"avatarUrl": "https://artistsdb.com/artist/1",
"tracks": [
{
"name": "Heal the world",
"urlSlug": "heal-the-world"
},
{
"name": "Thriller",
"urlSlug": "thriller"
}
]
}
}
}
همانطور که از دادههای پاسخ بالا مشخص است، ما دادههای مورد نیاز هر دو منبع /artists و /tracks را تنها با یک تماس API به دست آوردهایم. این یک ویژگی قدرتمند است که GraphQL ارائه میدهد. همانطور که تصور میکنید، کاربردهای این ویژگی برای ساختارهای API اظهاری بی حد و حصر است.
سازگاری مدرن
برنامههای مدرن امروزه به روشهای جامعی تعبیه شدهاند که در آن، تنها یک برنامه backend، دادههای مورد نیاز برای اجرای چندین کلاینت را تأمین میکند. برنامههای وب، برنامههای تلفن همراه، صفحه نمایشهای هوشمند، ساعتها و غیره تنها میتوانند به یک برنامه backend وابسته باشند تا دادهها به طور موثر کار کنند.
GraphQL از این روندهای جدید استقبال میکند؛ زیرا میتواند بدون اختصاص API جداگانه برای هر کلاینت، برای اتصال برنامه Backend و برآورده سازی نیازهای هر کلاینت (روابط تو در تو از دادهها، واکشی تنها دادههای مورد نیاز، نیازهای استفاده از شبکه و غیره) مورد استفاده قرار گیرد.
در بیشتر مواقع، برای انجام این کار، backend به چندین microservice با ویژگیهای متمایز تقسیم میشود. به این ترتیب اختصاص دادن ویژگیهای خاص به این microserviceها از طریق آنچه ما schema stitching مینامیم آسان است. schema stitching ایجاد یک طرح کلی از طرحهای مختلف را امکان پذیر میکند. در نتیجه، هر microservice میتواند طرح GraphQL خود را تعریف نماید.
پس از آن میتوانید از schema stitching استفاده کنید تا تمام طرحهای جداگانه را در یک طرح کلی بگنجانید که سپس توسط هر یک از برنامههای کلاینت قابل دسترسی باشد. در پایان، هر microservice میتواند نقطه پایانی GraphQL خود را داشته باشد، در حالی که یک درگاه GraphQL API، همه طرحها را در یک طرح سراسری تلفیق میکند تا در دسترس برنامههای کلاینت قرار گیرد.
برای نشان دادن schema stitching، بیایید ضمن شرح نحوه انجام stitching در جایی که دو API مرتبط داریم، وضعیت مشابه استفاده شده توسط Sakho Stubailo را در نظر بگیریم. در این مثال دو API را در نظر بگیرید: اول API جدید public Universes GraphQL برای سیستم مدیریت رویداد Ticketmaster’s Universe و دوم API مربوط به Dark Sky weather در Launchpad که توسط Matt Dionis ایجاد شده است. اکنون بیایید دو کوئری را بررسی کنیم که میتوانیم به طور جداگانه در برابر این APIها اجرا نماییم. ابتدا با Universe API میتوانیم جزئیات مربوط به شناسه یک رویداد خاص را به صورت زیر بدست آوریم:
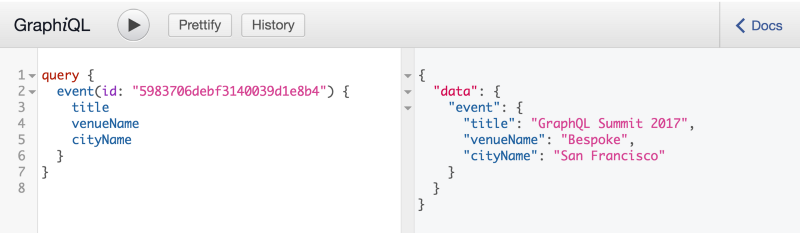
سپس با استفاده از API مربوط به Dark sky weather میتوانیم، جزئیات مربوط به همان مکان را به صورت زیر بدست آوریم:
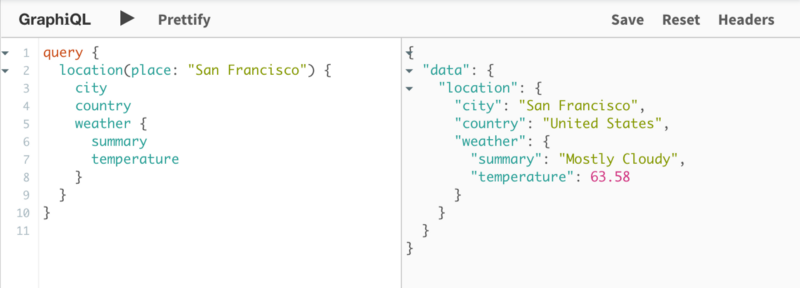
اکنون با GraphQL schema stitching میتوانیم عملیاتی را برای ادغام دو طرح به گونهای انجام دهیم که بتوانیم به راحتی آن دو کوئری را در کنار هم ارسال نماییم:
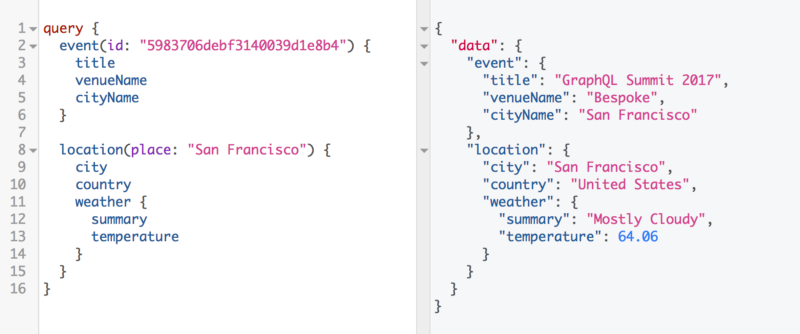
شما میتوانید نگاهی عمیق به طرح GraphQL schema stitching ایجاد شده توسط Sashko Stubailo داشته باشید تا درک عمیقتری از مفاهیم موجود بدست آورید.
به این ترتیب، GraphQL امکان ادغام طرحهای مختلف را در یک طرح کلی فراهم میکند که در آن همه کلاینتها میتوانند از این طریق منابع را بدست آورده و به راحتی سبک جدید توسعه مدرن را بپذیرند.
توسعه ورژنهای مختلف یک API
ما به عنوان توسعه دهنده عادت کردهایم که نسخههای مختلف API را فراخوانی کنیم و اغلب اوقات پاسخهای بسیار عجیبی دریافت مینماییم. از نظر کلاسیک، ما وقتی نسخه APIها را تغییر میدهیم که در منابع یا ساختار منابعی که در حال حاضر داریم، تغییراتی ایجاد کرده باشیم که در این صورت نیاز به استناد و تکامل به نسخه جدید داریم.
به عنوان مثال میتوانیم یک API مانند api.domain.com/resources/v1 داشته باشیم و در ماهها یا سالهای بعد، چند تغییر اتفاق میافتد و منابع یا ساختار منابع تغییر میکنند؛ از این رو، بهترین کار تغییر نسخه این API به نسخه api.domain.com/resources/v2 برای گرفتن تمام تغییرات اخیر است.
در این مرحله، برخی از منابع در v1 منسوخ میشوند (یا تا زمانی که کاربران به نسخه جدید مهاجرت نکنند، برای مدتی فعال باقی میمانند) و با دریافت درخواست برای این منابع، پاسخهای غیرمنتظرهای مانند deprecation notices دریافت میکنند.
در GraphQL میتوانید API را برروی یک سطح فیلد منسوخ کرد. بدین معنی که وقتی قرار است یک فیلد خاص منسوخ شود، کلاینت هنگام جستجوی فیلد با اخطار deprecation رو به رو میشود. پس از مدتی، هنگامیکه تعداد زیادی از کلاینتها از آن استفاده نمیکنند، فیلد منسوخ شده از طرح حذف میشود.
در نتیجه، به جای تغییر کامل نسخه API، میتوان به تدریج API را تکامل بخشید بدون اینکه نیازی به بازسازی کل طرح API باشد.
حافظه پنهان
استفاده از حافظه پنهان به منظور ذخیره سازی دادهها است تا درخواستهای بعدی برای آن دادهها سریعتر پاسخ داده شود. دادههای ذخیره شده در یک حافظه پنهان ممکن است نتیجه محاسبات اخیر یا کپی دادههای ذخیره شده در جای دیگر باشد. هدف از ذخیره سازی پاسخ API در درجه اول به دست آوردن سریعتر پاسخ درخواستهای آینده است. برخلاف GraphQL، مکانیزم حافظه پنهان در مشخصات HTTP تعبیه شده است که APIهای RESTful میتوانند از آن استفاده نمایند.
در REST با استفاده از URLها می توانید به منابع دسترسی پیدا کنید؛ بنابراین میتوانید حافظه پنهان را در سطح منبع داشته باشید؛ زیرا آدرس URL منبع را به عنوان شناسه دارید. در GraphQL، این مسئله پیچیده میشود؛ زیرا هر کوئری میتواند متفاوت باشد حتی اگر برروی یک موجودیت انجام شود.
در مثال ابتدای این مقاله، در یک کوئری ممکن است تنها نام یک هنرمند بخواهید؛ اما در کوئری بعدی ممکن است بخواهید آهنگهای هنرمندان و تاریخ انتشار آنها را بدست آورید. این همان نقطهای است که در آن استفاده از حافظه پنهان پیچیده است زیرا در این حالت به ذخیره حافظه پنهان در سطح فیلد نیاز دارد که دستیابی به آن با GraphQL (که از یک نقطه پایانی واحد استفاده میکند) کار سادهای نیست.
با این حال، انجمن GraphQL این دشواری را تشخیص داده و از آن زمان در تلاش است تا استفاده از حافظه پنهان را برای کاربران GraphQL راحتتر کند. کتابخانههایی مانند Prisma و Dataloader ( که در GraphQL استفاده میشود) برای کمک به سناریوهای مشابه ساخته شدهاند. با این حال، هنوز هم مواردی مانند مرورگر و حافظه پنهان تلفن همراه را به طور کامل پوشش نمیدهد.
عملکرد کوئری
GraphQL به کلاینتها این توانایی را میدهد تا کوئریها را برای بدست آوردن آنچه دقیقاً نیاز دارند، اجرا کنند. این یک ویژگی شگفت انگیز است؛ اما ممکن است کمی بحث برانگیز نیز باشد؛ زیرا میتواند به این معنی نیز باشد که کاربران میتوانند در هر تعداد منبع که بخواهند، قسمتهای مختلف را درخواست نمایند.
به عنوان مثال، فرض کنید کاربری یک کوئری را تعریف میکند که در آن لیستی از همه کاربرانی را میخواهد که در مورد تمام آهنگهای یک هنرمند خاص نظر دادهاند. برای این کار به یک کوئری مشابه زیر نیاز است:
artist(id: '1') {
id
name
tracks {
id
title
comments {
text
date
user {
id
name
}
}
}
}
این کوئری به طور بالقوه میتواند دهها هزار داده در پاسخ ارائه کند.
بنابراین، به همان اندازه که اجازه دادن به کاربران برای درخواست هر آنچه که نیاز دارند، در سطوح خاصی از پیچیدگی امری خوب است، درخواستهایی از این دست میتوانند سرعت عملکرد را کاهش داده و تأثیر بسیار زیادی بر کارایی برنامههای GraphQL بگذارند.
برای کوئریهای پیچیده، طراحی REST API ممکن است آسانتر باشد؛ زیرا شما میتوانید چندین نقطه پایانی را برای نیازهای خاص داشته باشید و برای هر نقطه پایانی میتوانید کوئریهای خاصی را به منظور بازیابی دادهها به روشی کارآمد تعریف کنید. این ممکن است کمی بحث برانگیز باشد که چندین تماس شبکه می تواند زمان زیادی را نیز به خود اختصاص دهد؛ بنابراین اگر مراقب نباشید، تنها چند کوئری بزرگ میتواند سرور شما را به زانو درآورد.
عدم تطابق دادهها
همانطور که قبلاً در هنگام ساختن GraphQL برروی backend مثال زدیم، در مواردی پایگاه داده شما و GraphQL API دارای طرحهای مشابه اما متفاوت هستند که به ساختارهای مختلف اسناد ترجمه میشوند. در نتیجه، یک track از پایگاه داده دارای ویژگی trackId خواهد بود؛ در حالی که همان track دریافت شده از طریق API شما دارای ویژگی track دیگری بر روی آن کلاینت است. این باعث عدم تطابق دادههای سمت کلاینت و سرور میشود.
به عنوان مثال، در نظر گرفتن نام هنرمند یک آهنگ خاص در سمت کلاینت، به این شکل خواهد بود:
const getArtistNameInServer = track => {
const trackArtist = Users.findOne(track.userId)
return trackArtist.name
}
در حالیکه، انجام دقیقاً همان کار در سمت سرور، کدی کاملاً متفاوت مانند زیر را در پی خواهد داشت:
const getArtistNameInServer = track => {
const trackArtist = Users.findOne(track.userId)
return trackArtist.name
}
این بدان معناست که شما از رویکرد عالی GraphQL در زمینه جستجوی داده در سرور غافل شدهاید.
خوشبختانه این مشکل قابل حل است. به نظر میرسد که شما میتوانید کوئریهای GraphQL سرور با سرور را به خوبی اجرا کنید. چطور؟ شما میتوانید این کار را با انتقال برنامه اجرایی GraphQL به تابع GraphQL، همراه با کوئری GraphQL خود انجام دهید:
const result = await graphql(executableSchema, query, {}, context, variables);
به گفته Sesha Greif، نباید GraphQL را تنها یک پروتکل خالص سرور-کلاینت ببینیم؛ بلکه از GraphQL میتوان برای جستجوی دادهها در هر شرایطی، از جمله کلاینت با کلاینت با Apollo Link State یا حتی در طی مراحل ساخت ایستا با Gatsby استفاده کرد.
شباهتهای طرح
هنگام ساخت GraphQL برروی backend، به نظر نمیرسد که بتوانید از تکرار کد جلوگیری کنید، به خصوص هنگامیکه صحبت از طرحها میشود. در ابتدا شما به یک طرح برای پایگاه داده خود و سپس برای نقطه پایانی GraphQL خود نیاز دارید. این شامل کدهای مشابه، اما نه کاملاً یکسان است، خصوصاً وقتی صحبت از طرحها میشود.
به اندازه کافی سخت است که شما مجبورید مرتباً کدهای بسیار مشابهی را برای طرحهای خود بنویسید؛ اما اینکه شما مجبور باشید مدام آنها را به طور همگام نگه دارید ناامیدکنندهتر است.
ظاهرا توسعه دهندگان دیگر متوجه این مشکل شدهاند و تاکنون انجمن GraphQL تلاشهایی به منظور رفع این مشکل انجام دادهاند. در زیر، دو مورد از محبوبترین اصلاحات ارائه شده است:
- PostGraphile که یک طرح GraphQL از پایگاه داده PostgreSQL شما ایجاد میکند.
- Prisma که به شما کمک میکند، type مختلفی را برای کوئریهای خود ایجاد نمایید.
منبع:
 پیدا کردن مک آدرس در سیستم های لینوکس
پیدا کردن مک آدرس در سیستم های لینوکس  Kubernetes یا همان K8S چیست؟ آشنایی مقدماتی Kubernetes
Kubernetes یا همان K8S چیست؟ آشنایی مقدماتی Kubernetes  نصب Flask در Ubuntu 20.04
نصب Flask در Ubuntu 20.04  افزودن کاربر و نویسنده جدید به وبلاگ وردپرس
افزودن کاربر و نویسنده جدید به وبلاگ وردپرس
0 دیدگاه
نوشتن دیدگاه