
Kubernetes، یک سیستم منبع باز قدرتمند است که در ابتدا توسط گوگل برای مدیریت برنامههای حاوی container در یک محیط کلاستری توسعه یافته است. هدف Kubernetes ارائه روشهای بهتر مدیریت و توزیع اجزا و سرویسها در زیرساختهای متنوع است.
در این راهنما، در مورد برخی از مفاهیم اساسی Kubernetes بحث شده است. در اینجا در مورد معماری سیستم، مشکلاتی که این سیستم حل میکند و مدل استفاده شده برای مدیریت Deploymentها و مقیاس بندی توضیح داده شده است.
Kubernetes چیست؟
Kubernetes، در سطح ابتدایی خود، سیستمی برای اجرا و هماهنگی برنامههای حاوی container در بین مجموعهای از ماشینها است. این سیستم، پلتفرمی است که برای مدیریت کامل چرخه حیات برنامهها و سرویسهای حاوی container طراحی شده است و از روشهایی استفاده میکند که قابلیت پیش بینی، مقیاس پذیری و دسترسی بالایی را فراهم مینماید.
شما به عنوان یک کاربر Kubernetes میتوانید نحوه اجرای برنامههای خود و راههای ارتباط آنها با سایر برنامهها یا دنیای خارج را تعیین کنید. با استفاده از آن، شما میتوانید مقیاس پذیری سرویسهای خود را تعیین نمایید، به روزرسانیهای مناسبی را انجام دهید و به منظور آزمایش ویژگیها و پیدا کردن مشکلات، ترافیک را بین نسخههای مختلف برنامههای خود جابهجا کنید. Kubernetes محیطی شامل رابطها و عناصر سازگار با یک پلتفرم را فراهم میکند که به شما امکان میدهد، برنامههای خود را با درجه انعطاف پذیری، قدرت و قابلیت اطمینان بالایی تعریف و مدیریت نمایید.
معماری Kubernetes
برای درک اینکه چگونه Kubernetes قادر به ارائه این قابلیتها است، درک نحوه طراحی و سازماندهی آن در سطح بالا مفید است. Kubernetes را میتوان بصورت سیستمی لایهای مشاهده کرد؛ بطوریکه هر لایه بالاتر پیچیدگی موجود در سطوح پایین را حذف میکند.
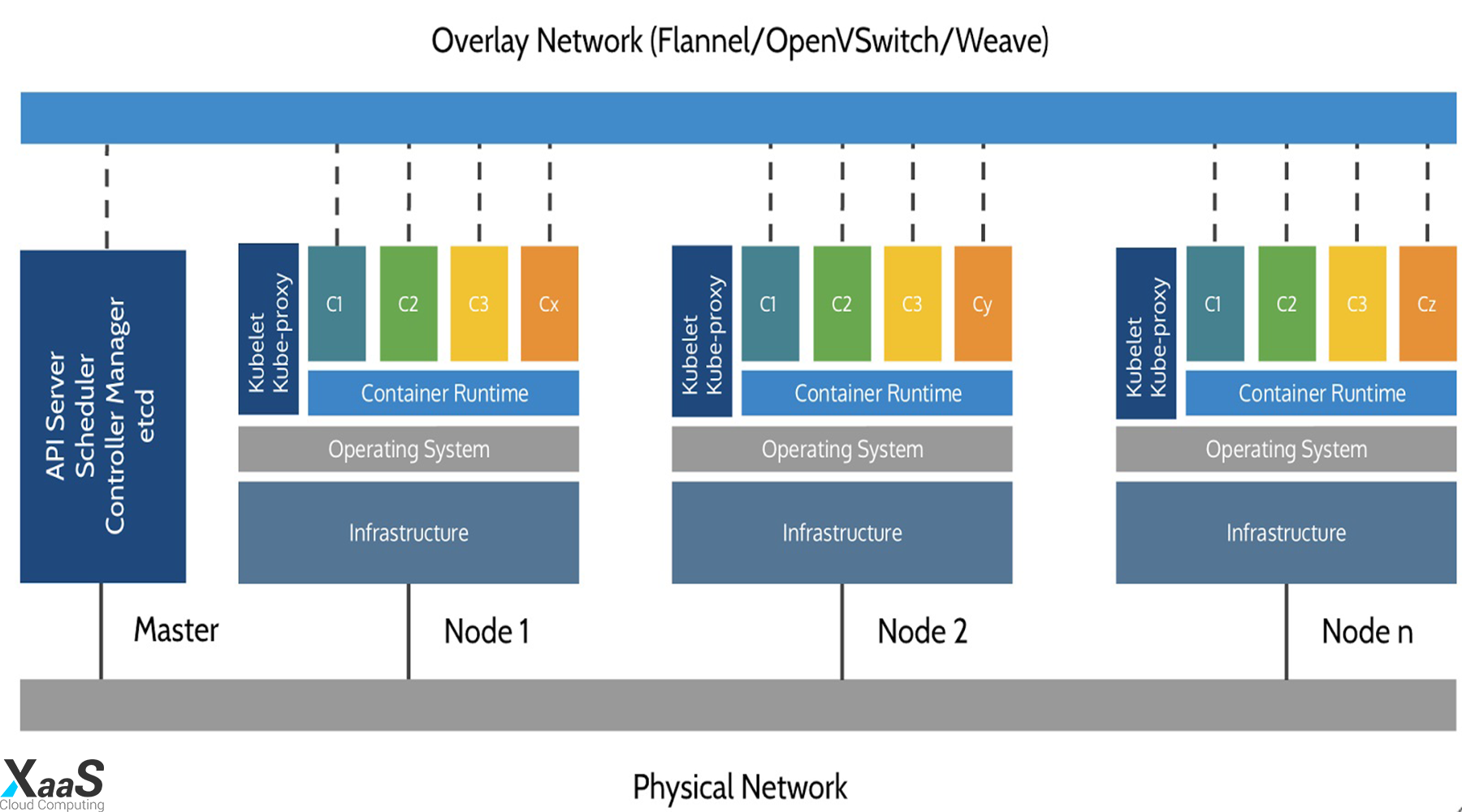
در پایگاه خود، Kubernetes با استفاده از یک شبکه مشترک برای برقراری ارتباط بین هر سرور، ماشینهای مجازی یا فیزیکی جداگانه را در یک کلاستر جمع میکند. این مجموعه، یک بستر فیزیکی است که در آن تمام اجزای Kubernetes، قابلیتها و workloadها پیکربندی شده است.
هر یک از ماشینهای موجود در این مجموعه، در اکوسیستم Kubernetes دارای نقشی هستند. یک سرور (یا گروه کوچکی در Deploymentهایی با دسترسی بسیار بالا) به عنوان سرور master کار میکند. این سرور با قرار دادن یک API برای کاربران و کلاینتها، بررسی سلامت سرورهای دیگر، تصمیم گیری در مورد بهترین روش تقسیم و تخصیص کار (معروف به "scheduling") و تنظیم هماهنگی ارتباطات بین سایر مولفهها، به عنوان یک gateway و مرکز برای cluster عمل میکند. سرور master به عنوان نقطه اصلی ارتباط با کلاستر عمل میکند و مدیریت و نظارت متمرکز در سراسر سیستم Kubernetes را فراهم مینماید.
سایر ماشینهای موجود در کلاستر به عنوان node تعیین میشوند. این ماشینها، سرورهایی هستند که مسئولیت پذیرش و اجرای workloadها را با استفاده از منابع محلی و خارجی بر عهده دارند. برای کمک به استقلال برنامه، مدیریت و انعطاف پذیری، Kubernetes، برنامهها و سرویسها را در containerها اجرا میکند؛ بنابراین هر node باید به container runtime (مانند Docker یا rkt) مجهز شود. node، دستورالعملهای کار را از سرور master دریافت کرده و containerهای مربوطه را ایجاد مینماید و یا از بین میبرد؛ همچنین قوانین شبکه را برای مسیریابی و هدایت ترافیک به طور مناسب تنظیم میکند.
همانطور که در بالا ذکر شد، برنامهها و سرویسها در کلاستر kubernete با containerها اجرا میشوند. مؤلفههای اساسی تضمین میکنند که حالت مطلوب برنامهها با وضعیت واقعی کلاستر مطابقت دارد. کاربران از طریق ارتباط مستقیم با سرور اصلی API یا با کلاینتها و کتابخانهها با کلاستر ارتباط برقرار میکنند. به منظور راهاندازی یک برنامه یا سرویس، یک طرح در JSON یا YAML ارائه میشود که مشخص میکند چه چیزی ایجاد شود و چگونه باید مدیریت گردد. سپس سرور master طرح را گرفته و نحوه اجرای آن برروی زیرساختها را با بررسی الزامات و وضعیت فعلی سیستم مشخص میکند. این گروه از برنامههای تعریف شده توسط کاربر که طبق یک طرح مشخص اجرا میشوند، لایه نهایی Kubernetes را نشان میدهد.
مولفههای سرور master
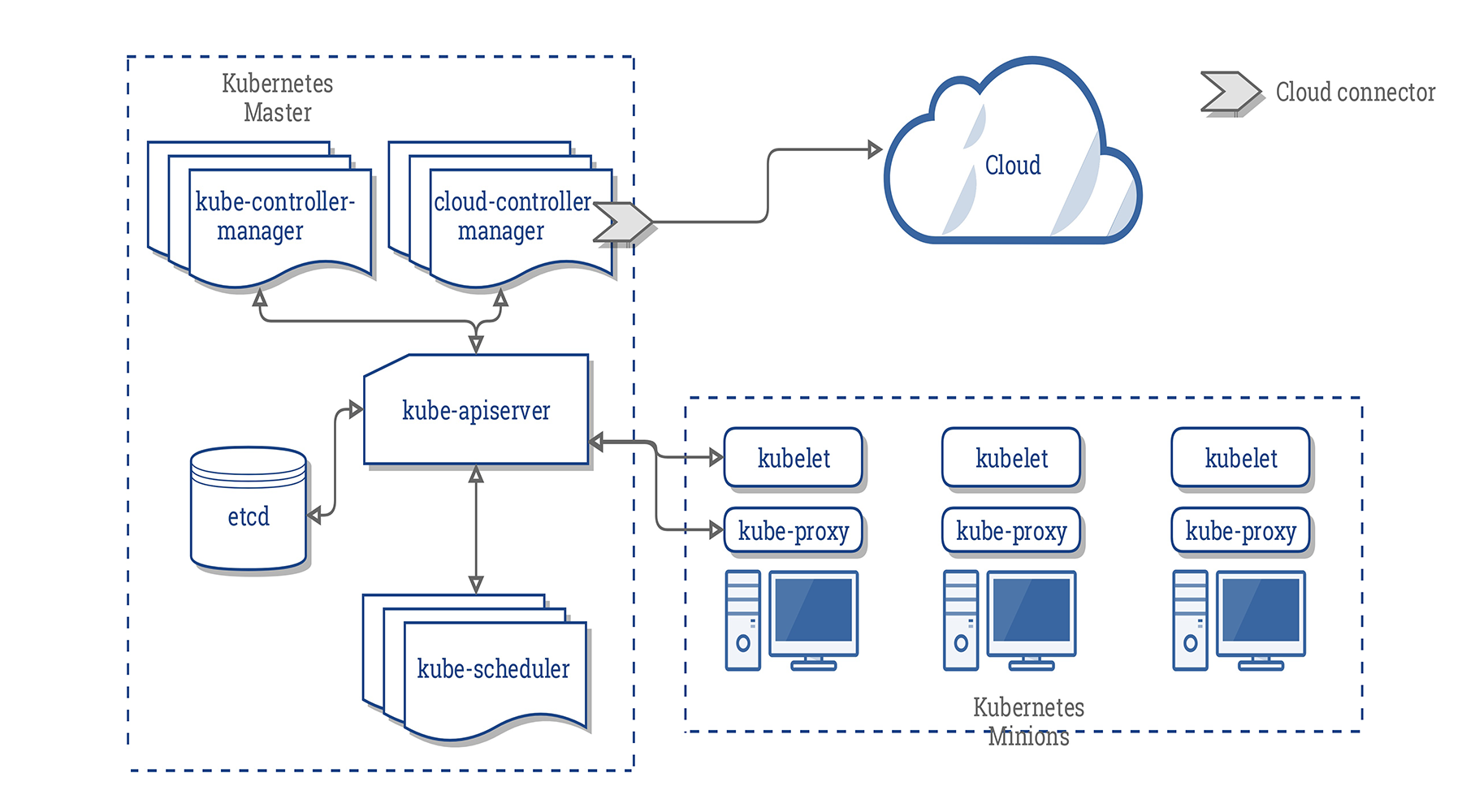
همانطور که در بالا شرح داده شد، سرور master به عنوان کنترل کننده اصلی برای کلاسترهای Kubernetes عمل میکند. این سرور به عنوان نقطه ارتباطی اصلی برای مدیران و کاربران در نظر گرفته میشود و بسیاری از سیستمهای کلاستری گسترده را برای nodeهای داخل کلاسترهای پیچیده فراهم میکند. به طور کلی، اجزای موجود در سرور master با هم کار میکنند تا درخواستهای کاربر را بپذیرند، بهترین روشها را برای تعیین زمان بارگیری containerها مشخص کنند، اعتبار کلاینتها و nodeها را تأیید نمایند، شبکه را در یک کلاستر گسترده تنظیم کنند و مسئولیتهای مقیاس پذیری و بررسی سلامت را مدیریت نمایند.
این مؤلفهها میتوانند روی یک ماشین نصب شده یا در چندین سرور توزیع شوند. در این بخش به تک تک اجزای مرتبط با سرورهای master نگاهی خواهیم انداخت.
etcd
یکی از مؤلفههای اساسی مورد نیاز Kubernetes ذخیره پیکربندی بصورت سراسری (در دسترس همه) است. پروژه etcd که توسط تیم CoreOS ساخته شده است، یک حافظه سبک و توزیع شده با مقدار کلیدی است که میتواند به گونهای تنظیم شود که در چندین node گسترش یابد.
Kubernetes از etcd برای ذخیره دادههای پیکربندی استفاده میکند که توسط هر یک از nodeهای کلاستر قابل دسترس است. این سرویس میتواند جهت جستجوی سرویسها، پیکربندی یا پیکربندی مجدد خودشان جهت بروز نگهداشتن اطلاعات استفاده شود. همچنین به حفظ حالت کلاستری با ویژگیهایی مانند انتخاب رهبر و قفل توزیع شده کمک میکند. با ارائه یک API ساده HTTP/JSON، رابط کاربری برای تنظیم یا بازیابی مقادیر بسیار آسان است.
مانند اکثر مؤلفههای دیگر، etcd را میتوان در یک سرور master پیکربندی کرد و یا در سناریوهای تولید، بین تعدادی از ماشینها توزیع نمود. تنها شرط این است که برای هر یک از دستگاههای Kubernetes از طریق شبکه قابل دسترس باشد.
kube-apiserver
یکی از مهمترین سرویسهای master، سرور API است. این سرویس، نقطه اصلی مدیریت کل کلاستر است؛ زیرا به کاربر اجازه میدهد تا workloadها و واحدهای سازمانی Kubernetes را پیکربندی کند. همچنین مسئولیت تضمین سازگاری حافظه و سرویسهای مستقر در container را به عهده دارد. این سرور در واقع به عنوان پلی بین اجزای مختلف به منظور نگهداری کلاستر و انتشار اطلاعات و دستورات عمل میکند.
سرور API یک رابط RESTful را پیاده سازی میکند؛ به این معنی که ابزارها و کتابخانههای مختلفس میتوانند به راحتی با آن ارتباط برقرار کنند. کلاینتی به نام kubectl به عنوان یک روش پیش فرض برای تعامل با مجموعه Kubernetes از طریق یک رایانه محلی در دسترس است.
kube-controller-manager
مدیر کنترل، یک سرویس سراسری است که مسئولیتهای زیادی دارد. در درجه اول، کنترل کنندههای مختلفی را کنترل میکند که آنها وضعیت کلاستر را تنظیم مینمایند، چرخههای حیاط workload را مدیریت میکنند و کارهای معمول را انجام میدهند. به عنوان مثال، یک Replication-Controller تضمین میکند که تعداد نسخههای مشابه تعریف شده برای یک pod مطابق با تعداد فعلی مستقر شده در کلاستر است. جزئیات این عملیات در etcd نوشته میشود که در آن، مدیر کنترل کننده از طریق سرور API تغییرات را مشاهده مینماید.
زمانی که تغییری مشاهده میشود، کنترل کننده اطلاعات جدید را خوانده و روندی که حالت مطلوب را برآورده میکند، اجرا مینماید. این میتواند شامل کوچک کردن یا بزرگ کردن یک برنامه، تنظیم نقاط انتهایی و غیره باشد.
Kube-scheduler
فرایندی که در واقع worklaodها را به nodeهای خاص در کلاستر اختصاص میدهد، scheduler (برنامه ریز) است. این سرویس، نیازهای عملیاتی workload را میخواند، محیط زیرساخت فعلی را تجزیه و تحلیل مینماید و work را در یک node یا node قابل قبول قرار میدهد.
scheduler، مسئول ردیابی container موجود در هر میزبان است تا اطمینان حاصل کند که workloadها بیش از منابع موجود برنامهریزی نشدهاند. scheduler باید از container کل و همچنین منابعی که قبلاً به workloadهای موجود در هر سرور اختصاص داده شده است، مطلع باشد.
cloud-controller-manager
Kubernetes میتواند در محیطهای مختلف مستقر شود و میتواند با ارائه دهندگان زیرساختهای مختلف برای درک و مدیریت وضعیت منابع در کلاستر تعامل داشته باشد. در حالی که Kubernetes با نمایشهای عمومی منابع مانند ذخیره سازی قابل اتصال و برقراری تعادل بار کار میکند؛ اما به روشی نیاز دارد که این منابع را به منابع واقعی ارائه شده توسط ارائه دهندگان ابر غیر همگن مرتبط نماید.
مدیران کنترل کننده ابر به Kubernetes اجازه میدهند با ارائه دهندگان با قابلیتها، ویژگیها و APIهای مختلف ارتباط برقرار کند؛ در حالی که ساختارهای نسبتاً عمومی را در داخل حفظ میکند. این به Kubernetes اجازه میدهد تا اطلاعات وضعیت خود را با توجه به اطلاعات جمع آوری شده از ارائه دهنده ابر به روز کند، منابع ابری را به دلیل تغییرات لازم در سیستم تنظیم کند و برای تأمین نیازهای کاری ارسال شده به کلاستر، سرویسها ابری اضافی ایجاد کرده و استفاده نماید.
اجزای سرور node
در Kubernetes، سرورهایی که با اجرای containerها کار میکنند، به عنوان nodeها شناخته میشوند. سرورهای node الزاماتی دارند که برای برقراری ارتباط با مؤلفههای master، پیکربندی شبکه container و اجرای workloadهای واقعی اختصاص یافته به آنها لازم است.
Container Runtime
اولین مؤلفه ای که هر node باید داشته باشد، container runtime است. به طور معمول، این نیاز با نصب و اجرای Docker برآورده میشود؛ اما گزینههای دیگری مانند rkt و runc نیز در دسترس هستند.
container runtime وظیفه راهاندازی و مدیریت containerها و برنامههای مستقل و سبک وزن محصور شده در یک محیط عملیاتی را دارد. هر واحد کار برروی مجموعه، در سطح پایه خود، به عنوان یک یا چند container که باید مستقر شوند، اجرا میشود. container runtime در هر node، مؤلفهای است که در نهایت containerهای تعریف شده در workload ارسال شده به کلاستر را اجرا میکند.
kubelet
نقطه اصلی ارتباط برای هر node با گروه کلاستر، سرویس کوچکی به نام kubelet است. این سرویس وظیفه انتقال اطلاعات بین سرویسهای مدیریتی و همچنین تعامل با حافظه etcd برای خواندن جزئیات پیکربندی یا نوشتن مقادیر جدید را دارد.
سرویس kubelet برای تأیید اعتبار در کلاستر و دریافت دستورات و وظایف با مؤلفههای master ارتباط برقرار میکند. وظایف به صورت یک manifest دریافت میشود و workload و پارامترهای عملیاتی را مشخص میکند. سپس فرآیند kubelet مسئولیت حفظ وضعیت کار را در سرور node بر عهده میگیرد. بدین صورت container runtime را کنترل میکند تا در صورت لزوم containerها را راهاندازی کرده و یا از بین ببرد.
kube-proxy
به منظور مدیریت subnetting جداگانه میزبان و در دسترس قرار دادن سرویسها برای سایر مولفهها، یک سرویس پراکسی کوچک به نام kube-proxy در هر سرور node اجرا میشود. این فرایند درخواستها را به containerهای صحیح هدایت میکند که این میتواند تعادل بار اولیه را انجام دهد و به طور کلی مسئولیت تضمین قابل پیش بینی بودن و قابلیت دسترسی به محیط شبکه (اما در صورت لزوم جدا) را به عهده دارد.
اشیا و Workloadهای Kubernetes
در حالی که containerها مکانیزم اساسی برای استقرار برنامهها هستند، Kubernetes از لایههای اضافی انتزاع بر روی رابط container استفاده میکند تا مقیاس بندی، انعطاف پذیری و ویژگیهای مدیریت چرخه حیات را فراهم کند. به جای مدیریت مستقیم containerها، کاربران اشیا اولیه مختلف ارائه شده توسط مدل شی Kubernetes را تعریف کرده و با آنها تعامل مینمایند. در ادامه، به شرح انواع مختلف اشیایی که میتواند برای تعیین این workloadها استفاده شود، پرداخته شده است.
Podها
pod اساسیترین واحدی است که kubernetes با آن سرو کار دارد. containerها خودشان به میزبان اختصاص داده نمیشوند؛ بلکه، یک یا چند container محکم بهم پیوسته و در شیئای به نام pod بستهبندی میشوند.
pod به طور کلی نشان دهنده یک یا چند container است که باید به عنوان یک برنامه کنترل شود. podها از containerهایی تشکیل شدهاند که از نزدیک با هم کار میکنند، چرخه حیات مشترک دارند و باید همیشه روی node یکسانی کار کنند. آنها به طور کامل به عنوان یک واحد مدیریت میشوند و محیط، volume و فضای IP خود را به اشتراک میگذارند. با توجه به اجرای آنها در یک container، شما باید podها را به عنوان یک برنامه یکپارچه در نظر بگیرید تا چگونگی مدیریت مجموعه و منابع و عملکرد pod را به بهترین شکل درک نمایید.
معمولاً podها از یک container اصلی تشکیل میشوند که هدف کلی workload و به طور اختیاری برخی از containerهای کمکی را برآورده میکند. اینها برنامههایی هستند که از اجرا و مدیریت در containerهای خود بهرهمند میشوند، اما کاملاً به برنامه اصلی node متصل هستند. به عنوان مثال، یک pod ممکن است دارای یک container باشد که سرور اصلی برنامه را اجرا میکند و دارای یک container کمکی باشد که (وقتی تغییرات در یک مخزن خارجی شناسایی میشود) فایلها را به سیستم فایل مشترک منتقل میکند. مقیاس بندی افقی به طور کلی در سطح pod تمام نمیشود؛ زیرا اشیا سطح بالاتر دیگری نیز وجود دارند که برای انجام این کار مناسبترند.
به طور کلی، کاربران نباید podها را مدیریت نمایند؛ زیرا برخی از ویژگیهای معمولاً مورد نیاز برنامهها (مانند مقیاسپذیری و مدیریت چرخه حیات پیچیده) را ارائه نمیدهند. در عوض، کاربران تشویق میشوند که با اشیا سطح بالاتری که از podها یا الگوهای pod به عنوان مؤلفههای پایه استفاده مینمایند (اما عملکردهای اضافی را اجرا میکنند)، کار نمایند.
کنترل کنندههای Replication و مجموعههای Replication
غالباً، هنگام کار با Kubernetes، به جای کار با podهای منفرد، گروههایی از podهای مشابه و تکرار شده را مدیریت خواهید کرد. اینها از الگوهای pod ایجاد شدهاند و میتوانند توسط کنترل كنندههایی كه به عنوان كنترل كنندههای replication و مجموعههای replicate شناخته میشوند، مقیاس بندی شوند.
کنترل کننده Replication، شیءای است که الگوی pod و پارامترهای کنترل برای مقیاس پذیری نسخههای مشابه یک pod را با افزایش یا کاهش افقی تعداد نسخههای در حال اجرا تعریف میکند. این یک روش آسان برای توزیع بار و افزایش در دسترس بودن در Kubernetes است. کنترل کننده replication میداند که چگونه در صورت لزوم podهای جدید ایجاد کند؛ زیرا یک الگویی که شباهت زیادی به تعریف pod دارد، در تنظیمات کنترل کننده replication تعبیه شده است.
کنترل کننده replication مسئول تضمین تطابق تعداد podهای مستقر در مجموعه با تعداد podهای داخل پیکربندی آن است. اگر یک pod یا میزبان اصلی خراب شود؛ کنترل کننده، podهای جدیدی را برای جبران خسارت راهاندازی میکند. اگر تعداد نسخههای کپی در پیکربندی کنترل کننده تغییر کند، کنترل کننده یا راهاندازی میشود یا containerها را از بین میبرد تا با شماره مورد نظر مطابقت داشته باشد. کنترل کنندههای replication همچنین میتوانند به روزرسانیهای جدید را انجام دهند تا مجموعهای از podها را یکی یکی به نسخه جدید منتقل کرده و تاثیر برروی قابلیت در دسترس بودن برنامه را به حداقل برساند.
مجموعههای replication، یک تکرار در طراحی کنترل کننده replication با انعطاف پذیری بیشتر در نحوه شناسایی کنترل کننده podهای مورد نظر برای مدیریت است. مجموعههای replication به دلیل قابلیتهای انتخاب replica بیشتر، جایگزین کنترل کنندههای replication میشوند؛ اما آنها قادر به انجام به روزرسانیهای جدید برای برگرداندن backendها به نسخه جدید مانند کنترل کنندههای replication نیستند. در عوض، مجموعههای replication باید در واحدهای سطح بالاتر و اضافی که این قابلیت را فراهم میکنند، استفاده شوند.
مانند podها، به ندرت با کنترل کننده replication و مجموعههای replication میتوان مستقیماً کار کرد. در حالی که آنها بر روی طراحی pod برای افزودن مقیاس پذیری افقی و ضمانتهای اطمینان کار میکنند، فاقد برخی از قابلیتهای مدیریت چرخه حیات مناسب (که در اشیا پیچیدهتر وجود دارد) هستند.
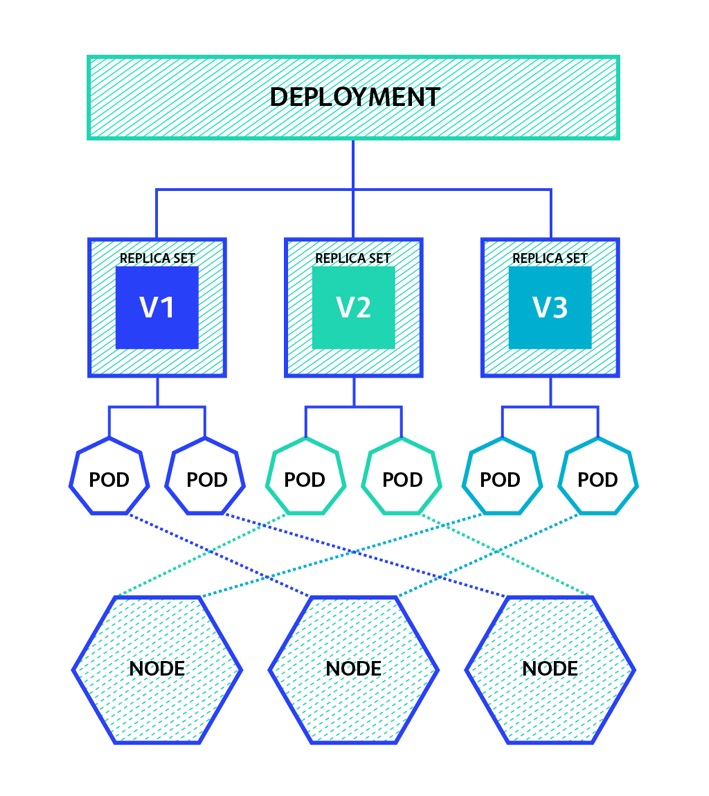
Deploymentها
Deploymentها یکی از متداولترین workloadها است که مستقیماً ایجاد و مدیریت میشود. Deploymentها از مجموعههای replication به عنوان یک عنصر سازنده استفاده مینمایند و قابلیت مدیریت انعطافپذیر چرخه حیات را به ترکیب اضافه میکنند.
در حالی که به نظر میرسد Deploymentهای ساخته شده با مجموعههای replication عملکرد ارائه شده توسط کنترل کنندههای replication را کپی میکنند، اما replication بسیاری از مشکلات موجود در اجرای به روزرسانیها را حل میکند. هنگام به روزرسانی برنامهها با کنترل کنندههای replication، کاربران ملزم به ارائه طرحی برای یک کنترل کننده replication جدید هستند که جایگزین کنترل کننده فعلی شود. هنگام استفاده از کنترل کنندههای replication، کارهایی مانند ردیابی تاریخچه، بازیابی به حالت قبل از شکست در شبکه در طول به روزرسانی و بازگرداندن به حالت قبل از تغییرات بد، یا دشوار است یا به عهده کاربر است.
Deploymentها یک شی سطح بالا هستند که برای سهولت در مدیریت چرخه حیات podهای تکرار شده طراحی شدهاند. Deploymentها را میتوان با تغییر پیکربندی به راحتی اصلاح کرد و Kubernetes مجموعههای replica را تنظیم مینماید، انتقالها را بین نسخههای مختلف برنامه مدیریت میکند، به صورت اختیاری تاریخچه رویداد را نگهداری مینماید و به طور خودکار قابلیت بازیابی را ارائه میدهد. به دلیل این ویژگیها، Deploymentها به احتمال زیاد یکی از اشیاء خواهد بود که شما بسیار با آن کار میکنید.
مجموعههای Stateful
مجموعههای Stateful، کنترل کنندههای pod ویژهای هستند که تضمینهای سفارش و منحصر به فرد بودن را ارائه میدهند. در درجه اول، این موارد برای کنترل دقیقتر هنگام نیازهای مربوط به سفارش استقرار، دادههای مداوم یا شبکه پایدار مورد استفاده قرار میگیرند. به عنوان مثال، مجموعههای stateful اغلب با برنامههای داده گرا مانند پایگاههای داده همراه هستند که حتی در صورت تنظیم مجدد به node جدید، نیاز به دسترسی به همان حجم را دارند.
مجموعههای Stateful با ایجاد یک نام منحصر به فرد و مبتنی بر عدد برای هر pod، یک شناسه شبکه پایدار را ارائه میدهند که حتی در صورت نیاز به انتقال pod به یک node دیگر وجود خواهد داشت. به همین ترتیب، در صورت لزوم به برنامه ریزی مجدد، حجم ذخیره سازی مداوم با یک pod قابل انتقال است. volumeها حتی پس از حذف pod برای جلوگیری از از بین رفتن تصادفی داده وجود خواهند داشت.
هنگام استقرار یا تنظیم مقیاس، مجموعههای stateful عملیات را با توجه به شناسه شماره گذاری شده در نام خود انجام میدهند. این امر باعث پیش بینی و كنترل بیشتر نسبت به ترتیب اجرا میشود كه در بعضی موارد میتواند مفید باشد.
مجموعههای Daemon
مجموعههای Daemon یک فرم تخصصی دیگر از کنترل کننده pod است که یک نسخه از یک pod را در هر node از مجموعه (یا در صورت مشخص بودن یک زیرمجموعه) اجرا میکند. این اغلب در هنگام استفاده از podهایی که در نگهداری و ارائه سرویسها برای خود nodeها کمک میکنند، مفید است.
به عنوان مثال، جمع آوری و ارسال گزارشهای مربوط، جمع آوری معیارها و اجرای سرویسهایی که قابلیتهای node را افزایش میدهند، نامزدهای محبوب مجموعههای daemon هستند. از آنجا که مجموعههای daemon غالباً سرویسهای اساسی را ارائه میدهند و به صورت سراسری مورد نیاز هستند، آنها میتوانند محدودیتهای زمانبندی pod را که مانع اختصاص pod به میزبانهای خاص توسط کنترل کنندهها میشود، دور بزنند. به عنوان مثال، به دلیل مسئولیتهای منحصر به فرد، سرور master به گونهای پیکربندی میشود که برای برنامه ریزی عادی pod در دسترس نباشد؛ اما مجموعههای daemon این توانایی را دارند که محدودیت را به صورت pod-by-pod بازنویسی کنند تا مطمئن شوند سرویسهای اساسی در حال اجرا هستند.
jobها و cron jobها
workloadهایی که تاکنون توصیف کردیم، همگی دارای چرخه حیات طولانی مدت و مشابه سرویس هستند. Kubernetes از یک workload به نام jobs استفاده میکند تا گردش کاری بیشتری را براساس وظایف ایجاد نماید که در آن، containerهای در حال اجرا پس از اتمام کار خود با موفقیت خارج میشوند. jobها در صورتی مفید هستند که شما به جای اجرای یک سرویس مستمر، نیاز به پردازش یکباره یا دستهای داشته باشید.
همانند cron daemonهای معمولی در لینوکس و سیستمهای مشابه یونیکس که اسکریپتها را بر اساس یک برنامه اجرا میکنند، cron jobها نیز در Kubernetes یک رابط برای اجرای jobها با یک مؤلفه scheduling فراهم میکند. Cron jobها میتوانند به منظور برنامهریزی اجرای یک job در آینده یا به صورت اجرای منظم و تکرار شونده مورد استفاده قرار گیرند. cron jobهای kubernetes اساساً یک اجرای مجدد رفتار cron کلاسیک است و از مجموعه به عنوان یک پلتفرم به جای یک سیستم عامل واحد استفاده مینماید.
سایر اجزای Kubernetes
فراتر از workloadها که میتوانید روی یک کلاستر اجرا نمایید، Kubernetes مولفههای دیگری را نیز در اختیار شما قرار میدهد که به شما کمک میکند، برنامههای خود را مدیریت کنید و شبکه را کنترل کرده و پایداری را فعال نمایید. ما در اینجا به چند مثال متداول خواهیم پرداخت.
سرویسها
تاکنون، ما از اصطلاح "service" در معنای متداول و در محیطهای لینوکسی استفاده کردهایم؛ بدین معنی که برای نشان دادن فرآیندهای طولانی مدت، اتصال به شبکه، پاسخگویی به درخواستها بکار بردهایم. با این حال در Kubernetes، سرویس مولفهای است که به عنوان یک توازن بار اصلی داخلی و مسئول podها عمل میکند. یک سرویس، مجموعههای منطقی podهایی را که عملکرد یکسانی را انجام میدهند، با هم گروه میکند تا آنها را به عنوان یک موجودیت واحد ارائه دهد.
این به شما امکان میدهد، سرویسی را پیاده سازی کنید که بتواند همه containerهای backend از یک نوع خاص را ردیابی و رهگیری نماید. مصرف کنندگان داخلی تنها باید در مورد نقطه پایانی پایدار ارائه شده توسط این سرویس بدانند. در همین حال، سرویسها به شما امکان میدهد، واحدهای کار backend را در صورت لزوم مقیاس بندی یا جایگزین نمایید. آدرس IP سرویس بدون در نظر گرفتن تغییرات podهای ردیابی شده، ثابت باقی میماند. با استقرار یک سرویس، میتوانید ردیابی را آسان کرده و طراحی container خود را سادهتر نمایید.
هر زمان که نیاز به دسترسی به یک یا چند pod به برنامه دیگر یا مصرف کنندگان خارجی دارید، باید یک سرویس را پیکربندی کنید. به عنوان مثال، اگر مجموعهای از podهای در حال اجرا برروی وب سرورهایی دارید که باید از طریق اینترنت قابل دسترس باشند، یک سرویس امکانات لازم را برای شما فراهم میکند. به همین ترتیب، اگر وب سرورهای شما نیاز به ذخیره و بازیابی اطلاعات دارند، میتوانید یک سرویس داخلی را پیکربندی نمایید تا امکان دسترسی به pod پایگاه داده شما را بدهد.
اگرچه سرویسها، به طور پیش فرض، تنها با استفاده از یک آدرس IP مسیریاب داخلی در دسترس هستند، اما میتوانند با انتخاب یکی از چندین استراتژیها، خارج از مجموعه نیز در دسترس قرار گیرند. پیکربندی NodePort با باز کردن یک پورت ثابت برروی هریک از رابطهای شبکه خارجی هر node کار میکند. بدین صورت ترافیک به پورت خارجی با استفاده از یک سرویس IP مجموعه داخلی به طور خودکار به podهای مناسب هدایت میشود.
متناوباً، سرویس LoadBalancer یک توازن بار خارجی را ایجاد میکند تا با استفاده از یکپارچه سازی تعادل دهنده بار Kubernetes مربوط به یک ارائه دهنده ابر، به سرویس منتقل شود. مدیر کنترل کننده ابر، منبع مناسب را ایجاد کرده و با استفاده از آدرسهای سرویس داخلی آن را پیکربندی مینماید.
Volumeها و Volumeهای ماندگار
به اشتراک گذاری قابل اعتماد دادهها و تضمین در دسترس بودن آنها در بین راهاندازی مجدد container در بسیاری از محیطهای حاوی container یک چالش است. runtimeهای container معمولاً مکانیزمی را برای اتصال فضای ذخیره سازی به یک containerای فراهم میکند که بیش از طول عمر آن container ماندگار است؛ اما پیاده سازیها معمولاً فاقد انعطاف پذیری هستند.
برای رفع این مسئله، Kubernetes از انتزاع volumeهای خاص خود استفاده میکند که اجازه میدهد دادهها توسط همه containerها درون یک pod به اشتراک گذاشته شوند و تا پایان pod در دسترس بمانند. این بدان معنی است که podهای کاملاً متصل میتوانند به راحتی فایلها را بدون مکانیسمهای پیچیده خارجی به اشتراک بگذارند. خرابی container در pod دسترسی به فایلهای مشترک را تحت تأثیر قرار نمیدهد. هنگامیکه pod خاتمه یافت، volume مشترک از بین میرود؛ بنابراین برای دادههای واقعاً پایدار راهحل خوبی نیست.
volumeهای پایدار، مکانیسمی برای حذف ذخیره قویتر است که به چرخه حیات pod مرتبط نیست. در عوض، آنها به مدیران اجازه میدهند، منابع ذخیره سازی را برای مجموعهای پیکربندی کنند که کاربران میتوانند برای podهای در حال اجرا درخواست و ادعا کنند. هنگامیکه یک pod با یک volume پایدار انجام میشود، سیاست احیای volume تعیین میکند که آیا volume تا زمانی که به طور دستی حذف نشود باقی میماند و یا اینکه همراه داده بلافاصله حذف میشود. از دادههای پایدار میتوان برای جلوگیری از خرابیهای مبتنی بر node و تخصیص میزان ذخیره بیشتر نسبت به میزان محلی در دسترس استفاده کرد.
برچسبها و یادداشتها
یکی دیگر از مؤلفههای Kubernetes برچسبها هستند. برچسب در Kubernetes یک تگ معنایی است که میتواند به اشیا Kubernetes متصل شود تا آنها را به عنوان بخشی از یک گروه مشخص نماید. سپس این اشیاء میتوانند در هدف قرار دادن موارد مختلف به منظور مدیریت یا مسیریابی انتخاب شوند. به عنوان مثال، هر یک از اشیا مبتنی بر کنترل کننده از برچسبها برای شناسایی podهایی استفاده میکنند که باید روی آنها کار کنند. سرویسها برای پیدا کردن podهای backendای که باید درخواستها را به آنها هدایت کنند، از برچسب استفاده مینمایند.
برچسبها به صورت جفتهای ساده با مقادیر کلیدی داده میشوند. هر واحد میتواند بیش از یک برچسب داشته باشد؛ اما هر واحد تنها میتواند یک ورودی برای هر کلید داشته باشد. معمولاً از کلید "name" به عنوان یک شناسه هدف کلی استفاده میشود؛ اما شما میتوانید اشیا را با معیارهای دیگر مانند مرحله توسعه، دسترسی عمومی، نسخه برنامه و غیره طبقه بندی کنید.
یادداشت نویسی، مکانیسم مشابهی است که به شما امکان میدهد اطلاعات با مقادیر کلیدی دلخواه را به یک شی متصل نمایید. در حالی که باید از برچسبها برای اطلاعات معنایی مفید به منظور تطبیق یک pod با معیارهای انتخابی استفاده شود، یادداشت نویسیها فرم آزادتری دارند و میتوانند حاوی دادههایی با ساختار یافتگی کمتر باشند. به طور کلی، یادداشت نویسی راهی برای افزودن metadataهای غنی به یک شیءای است که برای اهداف انتخابی مفید نیست.
منبع:
 نحوه بازنشانی آخرین commit در گیت (git)
نحوه بازنشانی آخرین commit در گیت (git)  تغییر پورت دایرکت ادمین
تغییر پورت دایرکت ادمین  آموزش Redirect در cPanel
آموزش Redirect در cPanel  نحوه عملکرد حافظه Swap در لینوکس
نحوه عملکرد حافظه Swap در لینوکس
0 دیدگاه
نوشتن دیدگاه