
هنگام طراحی یک پایگاه داده، ممکن است مواردی پیش بیاید که بخواهید محدودیتهایی (constraints) را به منظور تعیین دادههای مجاز برای ستونهای خاص اعمال کنید. این مقاله، به طور مفصل بررسی میکند که محدودیتهای پایگاه داده چیست و چگونه از آنها در RDBMS استفاده میشود. همچنین به شرح پنج محدودیت تعریف شده در استاندارد SQL پرداخته و توابع مربوطه آنها را شرح میدهد.
فرض کنید در حال ایجاد جدولی هستید که در آن باید اطلاعات مربوط به برجها قرار بگیرد. همانطور که میدانید، ستونی که ارتفاع برج را مشخص میکند نباید شامل مقادیر منفی باشد. این قانون را میتوان با استفاده از محدودیتهای پایگاه داده اعمال کرد.
این مطلب نیز ممکن است برای شما مفید باشد: پایگاه داده چیست؟ SQL چیست؟
سیستمهای مدیریت پایگاه داده رابطهای (RDBMS) به شما امکان میدهد، دادههای جداول را به کمک محدودیتها کنترل کنید. محدودیت (constraint) در پایگاه داده، یک قانون خاص است که برای یک یا چند ستون (یا برای یک جدول کامل) اعمال میشود و تغییرات ایجاد شده در دادههای جدول را چه از طریق عبارت INSERT ،UPDATE یا DELETE محدود میکند.
constraintها در پایگاه داده چیست؟
در SQL، محدودیت، هر قانونی است که بر روی یک ستون یا جدول اعمال میشود و اطلاعاتی را که میتوان در آن وارد کرد، محدود میکند. بدین معنی که هر زمان که بخواهید عملیاتی را انجام دهید که منجر به تغییر دادههای نگهداری شده در یک جدول میشود، بررسی میکند که آیا این دادهها محدودیتهای موجود را نقض میکند یا خیر و در صورت نقض شدن محدودیتها، خطایی را برمیگرداند.
مدیران پایگاه داده به منظور اطمینان از پیروی پایگاه داده از مجموعهای از قوانین تجاری مشخص، اغلب به این constraintها تکیه میکنند. در زمینه یک پایگاه داده، قوانین تجارت، هر خط مشی یا روشی است که یک سازمان تجاری یا سازمان دیگری از آن پیروی مینماید و دادههای آن نیز باید از آن پیروی کند. به عنوان مثال، فرض کنید در حال ساخت یک پایگاه دادهای هستید که موجودی یک فروشگاه را فهرست بندی میکند. اگر مدیر فروشگاه مشخص نماید که هر رکورد محصول باید یک شماره شناسایی منحصر به فرد داشته باشد، شما میتوانید یک ستون با یک محدودیت UNIQUE ایجاد کنید که تضمین مینماید، هیچ دو ورودی در آن ستون یکسان نخواهد بود.
محدودیتها همچنین برای حفظ یکپارچگی دادهها مفید هستند. یکپارچگی دادهها، اصطلاحی گسترده است که اغلب برای توصیف دقت، ثبات و منطقی بودن کلی دادههای نگهداری شده در یک پایگاه داده، بر اساس استفاده خاص آن بکار گرفته میشود. جداول موجود در یک پایگاه داده، اغلب از نزدیک با هم مرتبط هستند و ستونهای یک جدول به مقادیر جدول دیگر وابستهاند. از آنجایی که ورود اطلاعات غالباً در معرض محدودیتهای خطای انسانی است، محدودیتهای پایگاه داده در مواردی از این دست مفید است؛ زیرا میتواند تضمین کند که هیچ داده اشتباه وارد شدهای نمیتواند، بر چنین روابطی تأثیر بگذارد و بنابراین به یکپارچگی داده پایگاه داده آسیب برساند.
فرض کنید در حال طراحی یک پایگاه داده با دو جدول هستید: یکی برای لیست دانش آموزان فعلی در یک مدرسه و دیگری برای فهرست اعضای تیم بسکتبال آن مدرسه. شما میتوانید یک محدودیت FOREIGN KEY برای ستونی در جدول تیم بسکتبال اعمال کنید که به ستونی در جدول مدرسه اشاره دارد. با ایجاد این رابطه بین دو جدول، به ازای هر ورودی در جدول تیم بسکتبال یک رکورد باید در جدول دانش آموزان وجود داشته باشد تا ستون جدول تیم بسکتبال به آن رکورد اشاره کند.
کاربران میتوانند محدودیتهای مورد نظر رادر زمان ایجاد جدول یا پس از آن (به شرطی که با دادههای موجود در جدول مغایرت نداشته باشد)، به کمک یک عبارت ALTER TABLE اضافه نمایند. هنگامیکه محدودیتی ایجاد میکنید، سیستم پایگاه داده به طور خودکار نامی برای آن ایجاد میکند، اما در اکثر پیاده سازیهای SQL میتوانید، برای هر محدودیتی یک نام دلخواه انتخاب نمایید. این نامها برای اشاره به محدودیتها در عبارات ALTER TABLE هنگام تغییر یا حذف آنها استفاده میشود.
استاندارد SQL، به طور رسمی تنها پنج محدودیت را تعریف میکند:
- PRIMARY KEY (کلید اصلی)
- FOREIGN KEY (کلید خارجی)
- UNIQUE (منحصر بفرد بودن)
- CHECK (بررسی کردن)
- NOT NULL (تهی نبودن)
توجه: بسیاری از RDBMSها دارای کلمه کلیدی DEFAULT هستند که برای تعریف یک مقدار پیش فرض برای یک ستون استفاده میشود. در صورت تعیین نکردن مقداری برای DEFAULT، از مقدار NULL استفاده میشود. در اسناد برخی از این سیستمهای مدیریت پایگاه داده، DEFAULT به عنوان محدودیت ذکر میشود؛ زیرا در پیاده سازی SQL آنها، از دستور DEFAULT شبیه به محدودیتهایی مانند UNIQUE یا CHECK استفاده میشود. با این حال، DEFAULT از نظر فنی محدودیت به شمار نمیآید؛ زیرا دادههایی را که میتواند در یک ستون وارد شود، محدود نمیکند.
اکنون که به درک کلی از نحوه استفاده از محدودیتها رسیدهاید، بیایید نگاهی دقیق به هر یک از این پنج محدودیت بیندازیم.
PRIMARY KEY
برای محدودیت PRIMARY KEY باید هر ورودی در ستون مشخص شده، مخالف NULL و منحصر به فرد باشد. این محدودیت به شما امکان میدهد، برای شناسایی ردیفهای جدول، از آن ستون استفاده نمایید.
در مدل رابطهای، کلید، یک ستون یا مجموعهای از ستونها در یک جدول است که مقادیر آن بصورت منحصر به فرد و مخالف NULL است. primary key، یک کلید خاص است که مقادیر آن برای شناسایی هر ردیف (بصورت جداگانه) در یک جدول استفاده میشود. علاوه بر این، ستون یا ستونهایی که کلید اصلی را تشکیل میدهند، میتوانند برای شناسایی جدول در بقیه پایگاه داده استفاده شوند.
این، یک مسئله مهم در پایگاه دادههای رابطهای است که با داشتن یک primary key، کاربران نیازی به دانستن اینکه اطلاعات آنها به طور فیزیکی در کجا ذخیره میشود، ندارند و DBMS آنها میتواند هر رکورد را ردیابی کرده و آنها را به صورت موقت نمایش دهد. این بدان معنی است که رکوردها ترتیب منطقی مشخصی ندارند و کاربران توانایی مشاهده دادههای خود را با هر ترتیبی و یا از طریق فیلترهای مورد نظر دارند.
شما میتوانید با استفاده از محدودیت Primary KEY، یک کلید اصلی در SQL ایجاد کنید که در اصل ترکیبی از محدودیتهای UNIQUE و NOT NULL است. پس از تعریف یک کلید اصلی، DBMS به طور خودکار یک index مرتبط با آن ایجاد مینماید. index، یک ساختار پایگاه داده است که به بازیابی سریعتر دادهها از یک جدول کمک میکند. مشابه فهرست در یک کتاب، کوئریها تنها باید ورودیهای ستون فهرست بندی شده را برای یافتن مقادیر مرتبط بررسی نمایید. این همان چیزی است که به کلید اصلی اجازه میدهد تا به عنوان یک شناسه برای هر سطر در جدول عمل کند.
یک جدول میتواند تنها یک کلید اصلی داشته باشد؛ اما مانند کلیدهای معمولی، یک کلید اصلی میتواند بیش از یک ستون را تشکیل دهد. با این اوصاف، یک ویژگی تعیین کننده کلید اصلی این است که از حداقل ویژگیهای مورد نیاز برای شناسایی منحصر به فرد هر سطر در یک جدول استفاده کند.
به عنوان مثال، جدولی را تصور نمایید که با استفاده از سه ستون زیر، اطلاعات دانش آموزان یک مدرسه را ذخیره میکند:
- studentID: برای نگهداری شماره شناسایی منحصر به فرد هر دانش آموز استفاده میشود.
- firstName: برای نگهداری نام هر دانش آموز استفاده میشود.
- lastName: برای نگهداری نام خانوادگی هر دانش آموز استفاده میشود.
این امکان وجود دارد که برخی از دانش آموزان در مدرسه، یک نام مشترک داشته باشند. به همین دلیل ستون firstName به تنهایی نمیتواند به عنوان کلید اصلی انتخاب شود. این مورد، برای ستون lastName نیز صدق میکند. اگرچه یک کلید اصلی متشکل از ترکیب ستون firstName و LastName میتواند کار کند، اما همچنان نیز این احتمال وجود دارد که دو دانشجویی وجود داشته باشد که یک نام و نام خانوادگی مشترک داشته باشند.
یک کلید اصلی متشکل از ستون studentID به همراه یکی از ستونهای FirstName یا LastName اگرچه میتواند کار کند؛ اما از آنجایی که شماره شناسایی هر دانش آموز منحصر به فرد است، وجود هر یک از ستونهای نام در کلید اصلی اضافی است. بنابراین، با توجه به حداقل ویژگی برای شناسایی هر سطر، بهترین گزینه برای کلید اصلی جدول، ستون studentID به تنهایی است.
اگر یک کلید از دادههای برنامه قابل مشاهده (یعنی دادههایی که موجودیتها، رویدادها یا ویژگیهای دنیای واقعی را نشان میدهند) تشکیل شده باشد، از آن به عنوان یک کلید natural (طبیعی) یاد میشود. اگر کلید به صورت داخلی تولید شده باشد و نمایانگر چیزی خارج از پایگاه داده نباشد، به عنوان کلید surrogate (جایگزین) یا synthetic (مصنوعی) شناخته میشود. برخی از سیستمهای پایگاه داده استفاده از کلیدهای طبیعی را توصیه نمیکنند، زیرا حتی دادههای به ظاهر ثابت میتوانند از راههای غیرقابل پیش بینی تغییر نمایند.
FOREIGN KEY
محدودیت FOREIGN KEY مستلزم این است که هر ورودی در ستون مشخص شده، از قبل در یک ستون خاص از جدول دیگر وجود داشته باشد.
اگر دو جدول دارید که میخواهید با یکدیگر ارتباط دهید، یکی از راههای انجام این کار این است که یک کلید خارجی با محدودیت FOREIGN KEY تعریف کنید. کلید خارجی، ستونی در یک جدول (جدول "فرزند") است که مقادیر آن از یک کلید در جدول دیگر (جدول "والد") آمده است. این روشی برای بیان رابطه بین دو جدول است. بنابراین، برای محدودیت FOREIGN KEY ستونی که این محدودیت روی آن اعمال میشود، باید به ستونی اشاره کند که از قبل وجود داشته باشد.
نمودار زیر چنین رابطهای را بین دو جدول برجسته میکند: یکی برای ثبت اطلاعات مربوط به کارمندان یک شرکت استفاده شده و دیگری برای ردیابی فروش شرکت استفاده میشود. در این مثال، کلید اصلی جدول EMPLOYEES توسط کلید خارجی جدول SALES ارجاع میشود:
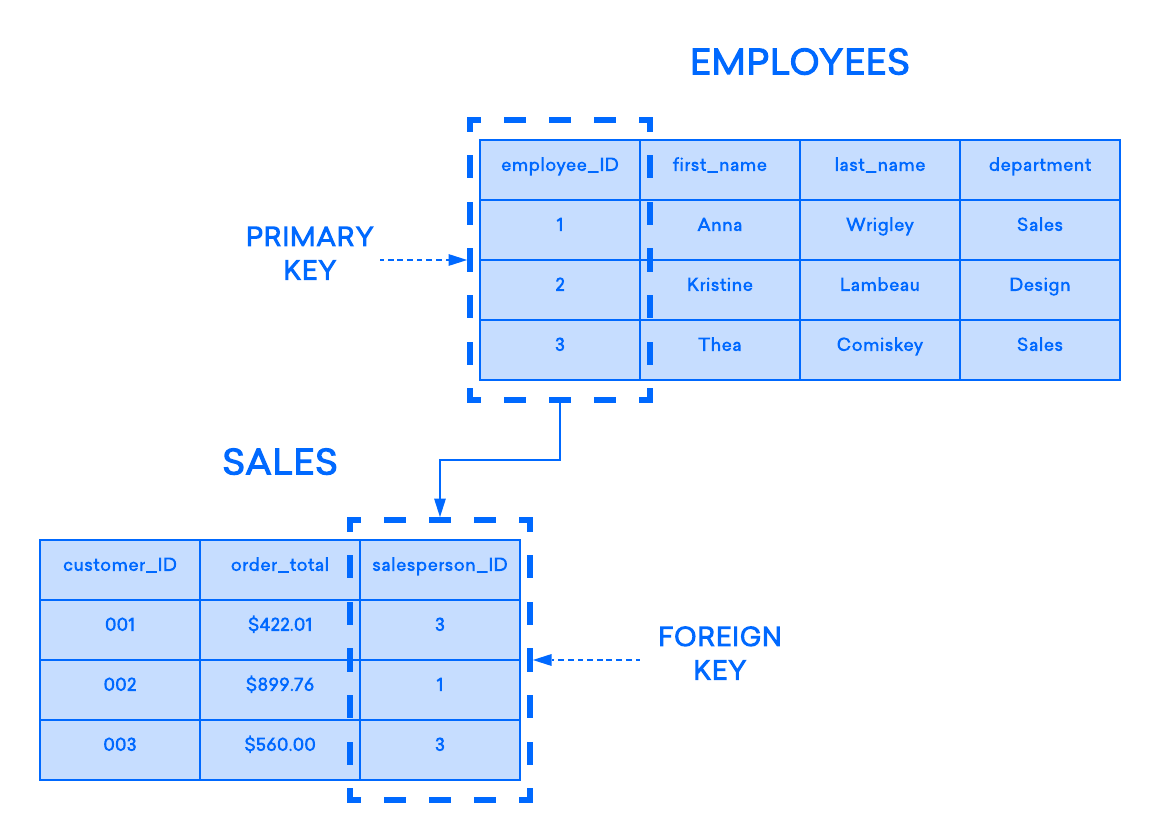
اگر بخواهید یک رکورد به جدول فرزند اضافه کنید؛ درحالیکه مقدار وارد شده در ستون کلید خارجی، در کلید اصلی جدول والد وجود نداشته باشد، چنین عملیاتی نامعتبر در نظر گرفته خواهد شد. این، به حفظ یکپارچگی در سطح رابطه کمک میکند؛ زیرا ردیفهای هر دو جدول همیشه به درستی مرتبط هستند.
اغلب اوقات، کلید خارجی یک جدول، کلید اصلی جدول والد است؛ اما همیشه اینطور نیست. در بیشتر RDBMSها، هر ستونی در جدول والد که دارای محدودیت UNIQUE یا PRIMARY KEY باشد، میتواند توسط کلید خارجی جدول فرزند اشاره شود.
UNIQUE
محدودیت UNIQUE، افزودن مقادیر تکراری به ستون مشخص شده را منع میکند.
همانطور که از نام آن پیداست، یک محدودیت UNIQUE باعث میشود، هریک از ورودیهای ستون مشخص شده، یک مقدار منحصر به فرد باشد. بنابراین، با اعمال این محدودیت، هرگونه تلاش برای افزودن مقداری که از قبل در ستون وجود دارد، منجر به نمایش خطا میشود.
محدودیتهای UNIQUE برای اجرای روابط یک به یک بین جداول مفید هستند. همانطور که قبلاً ذکر شد، شما میتوانید بین دو جدول با یک کلید خارجی رابطه برقرار کنید؛ اما انواع مختلفی از روابط میتواند بین جداول وجود داشته باشد:
- رابطه یک به یک (one-to-one): اگر هر ردیف از جدول والد تنها و تنها به یک ردیف در جدول فرزند مرتبط باشد، گفته میشود که دو جدول رابطه یک به یک دارند.
- رابطه یک به چند (one-to-many): در یک رابطه چند به یک، یک ردیف در جدول والد میتواند با چندین ردیف در جدول فرزند مرتبط باشد؛ اما هر ردیف در جدول فرزند تنها میتواند، به یک ردیف در جدول والد مربوط شود.
- رابطه چند به چند (many-to-many): در یک رابطه چند به چند، چند ردیف در جدول والد میتوانند، با چند ردیف در جدول فرزند مرتبط باشند و بالعکس.
با افزودن یک محدودیت UNIQUE به ستونی که محدودیت FOREIGN KEY روی آن اعمال شده است، میتوانید اطمینان حاصل کنید که هر ورودی در جدول والد، تنها یک بار در جدول فرزند نشان داده میشود؛ در نتیجه یک رابطه یک به یک بین دو جدول ایجاد میشود.
توجه داشته باشید که شما میتوانید، محدودیتهای UNIQUE را در سطح جدول و همچنین سطح ستون تعریف کنید. هنگامیکه در سطح جدول تعریف شود، یک محدودیت UNIQUE میتواند برای بیش از یک ستون اعمال شود. در مواردی از این دست، هر ستون موجود در محدودیت میتواند مقادیر تکراری داشته باشد؛ اما هر سطر باید ترکیبی منحصر به فرد از مقادیر را در ستونهای محدود شده داشته باشد.
CHECK
محدودیت CHECK، شرط خاصتری را برای ستونهای جدول تعریف میکند؛ بطوریکه هر مقدار وارد شده در آن ستون باید آن شرط را برآورده کند.
خروجیهای محدودیت CHECK در قالب عباراتی نوشته میشوند که میتوانند به صورت TRUE ،FALSE یا به طور بالقوه UNKNOWN ارزیابی شوند. زمانیکه مقداری را در یک ستون دارای محدودیت CHECK وارد نمایید؛ چنانچه خروجی آن TRUE یا UNKNOWN (که برای مقادیر NULL اتفاق میافتد) باشد، عملیات موفقیت آمیز خواهد بود. در غیر این صورت، اگر نتیجه FALSE شود، نشان دهنده این است که شرط برآورده نشده و ورود آن مقدار در جدول با شکست روبهرو شده است.
محدودیت CHECK اغلب برای محدود کردن بازه دادههای مجاز برای یک ستون، از عملگر مقایسه ریاضی (مانند <، >، <=، یا > =) استفاده مینمایند. به عنوان مثال، یک استفاده معمول از محدودیتهای CHECK، جلوگیری از وارد شدن مقادیر منفی برای برخی از ستونهایی است که مقدار منفی برای آنها منطقی نیست (مانند مثال زیر).
CREATE TABLE productInfo (
productID int,
name varchar(30),
price decimal(4,2)
CHECK (price > 0)
);
دستور CREATE TABLE جدولی به نام productInfo با ستونهایی برای نام، شماره شناسایی و قیمت هر محصول ایجاد میکند. از آنجا که منطقی نیست که کالایی قیمت منفی داشته باشد، این عبارت برای تضمین این مورد استفاده میشود که ستون قیمت تنها حاوی مقادیر مثبت باشد.
در محدودیت CHECK تنها از عملگرهای مقایسه ریاضی استفاده نمیشود؛ بلکه از هر عملگر SQL که منجر به نتیجه TRUE ،FALSE یا UNKNOWN میشود، از جمله LIKE ،BETWEEN ،IS NOT NULL و موارد دیگر نیز میتوان استفاده کرد. برخی از پیاده سازیهای SQL (نه تمام آنها)، حتی به شما امکان میدهند که یک subquery را در یک دستور CHECK قرار دهید. دقت کنید که اکثر پیاده سازیها به شما اجازه نمیدهند که در این محدودیت به جدول دیگری اشاره نمایید.
NOT NULL
محدودیت NOT NULL، افزودن مقادیر NULL را به ستون داده شده منع میکند.
در بیشتر پیاده سازیهای SQL، اگر یک ردیف داده اضافه کنید؛ اما برای یکی از ستونها مقداری را تعیین ننمایید، سیستم پایگاه داده به طور پیش فرض مقدار آن ستون را با NULL پر میکند. در SQL، مقدار NULL کلمه کلیدی خاصی است که برای نشان دادن یک مقدار ناشناخته، از دست رفته یا غیر مشخص استفاده میشود. با این حال، NULL، خود یک مقدار نیست بلکه در عوض حالت یک مقدار ناشناخته است.
برای نشان دادن این تفاوت، جدولی را تصور کنید که برای ردیابی مشتریان در یک آژانس استعدادیابی استفاده میشود که ستونهایی برای نام و نام خانوادگی هر مشتری دارد. اگر یک مشتری از یک اسم مستعار مانند "Cher"، "Usher" یا "Beyoncé" استفاده کند، مدیر پایگاه داده ممکن است، تنها نام مستعار را در ستون نام وارد نماید که باعث میشود، DBMS عبارت NULL را در ستون نام خانوادگی وارد کند. این بدان معنی نیست که پایگاه داده، نام خانوادگی مشتری را "Null" به حساب می آورد. بلکه این تنها به این معنی است که مقدار ستون نام خانوادگی آن سطر ناشناخته است یا این فیلد برای آن رکورد خاص اعمال نمیشود.
همانطور که از نام آن مشخص است، محدودیت NOT NULL مانع از NULL بودن مقادیری در ستون مورد نظر میشود. این بدان معنی است که برای هر ستون با محدودیت NOT NULL، باید هنگام قرار دادن یک ردیف جدید مقداری برای آن تعیین کنید. در غیر این صورت، عملکرد INSERT ناموفق خواهد بود.
منبع:
 حل مشکل بزرگ بودن فایل آپلود شده در وردپرس
حل مشکل بزرگ بودن فایل آپلود شده در وردپرس  ایجاد کاربر، پایگاه داده و افزودن دسترسی در PostgreSQL
ایجاد کاربر، پایگاه داده و افزودن دسترسی در PostgreSQL  چرا بکاپ (نسخه ی پشتیبانی) ؟
چرا بکاپ (نسخه ی پشتیبانی) ؟  بازیابی آخرین نسخه پشتیبان در دایرکت ادمین
بازیابی آخرین نسخه پشتیبان در دایرکت ادمین
0 دیدگاه
نوشتن دیدگاه