
Robots.txt یک فایل متنی است که مدیران وب ایجاد میکنند و به کمک آن، نحوه خزیدن (crawl کردن) صفحات وب سایت خود را به روباتهای وب (معمولاً روباتهای موتورهای جستجو) آموزش میدهند. فایل robots.txt بخشی از پروتکل حذف روباتها (REP) است. این پروتکل، مجموعهای از استانداردهای وب است که نحوه خزیدن روباتها در وب، دسترسی و فهرست بندی محتوا و ارائه آن محتوا به کاربران را تنظیم میکند. REP همچنین شامل دستورالعملهایی مانند meta robotها، و همچنین دستورالعملهای مربوط به صفحه، زیردایرکتوری یا کل سایت در جهت نحوه برخورد موتورهای جستجو با لینکها (به عنوان مثال "دنبال کردن" یا "دنبال نکردن") است.
در عمل، فایلهای robots.txt نشان میدهند که هر user agent (نرمافزار web-crawling) چه بخشهایی از یک وبسایت را میتواند crawl کند. این دستورالعملهای خزیدن (crawl کردن) با عبارت "اجازه ندادن (disallowing)" یا "اجازه دادن (allowing)" به رفتار آن user agentها تعیین میشوند.
این مطلب نیز ممکن است برای شما مفید باشد: Redirectها برای SEO
ساختار اصلی:
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
این دو خط کد با همدیگر یک فایل robots.txt کامل در نظر گرفته میشوند؛ اگرچه یک فایل ربات میتواند حاوی چندین خط از user agentها و دستورالعملها (به عنوان مثال، disallows ،allows ،crawl-delays و غیره) باشد.
در یک فایل robots.txt، هر مجموعه از دستورالعملهای user-agent بهعنوان یک مجموعه مجزا ظاهر میشود که با یک خط خالی از هم جدا شدهاند:
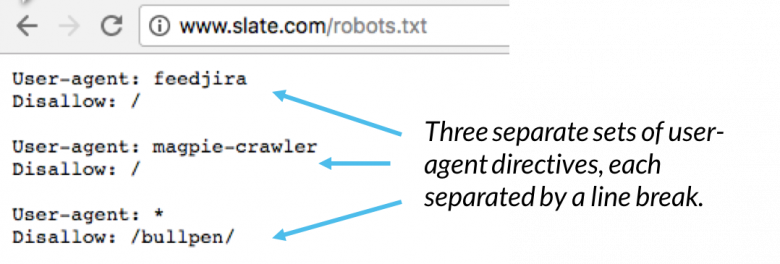
در یک فایل robots.txt با چندین user agent به همراه دستورالعملهای مربوطه، هر قانون غیر مجاز یا مجاز فقط برای user agentهای مشخص شده در آن مجموعه (که با یک خط خالی از هم جدا شده است) اعمال میشود. اگر فایل حاوی قانونی باشد که برای بیش از یک user agent اعمال میشود، crawler به خاصترین گروه دستورالعملها توجه میکند و آن دستورالعمل را دنبال مینماید.
به عنوان مثال:
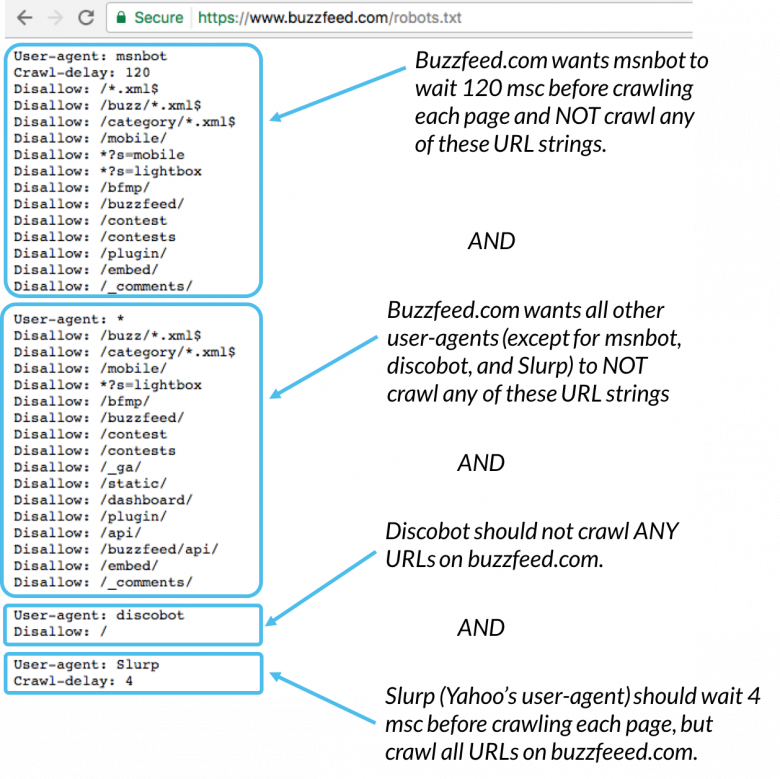
Msnbot ،discobot، و Slurp همه به طور خاص فراخوانی شدهاند؛ بنابراین این user agentها فقط به دستورالعملهای بخشهای خود از فایل robots.txt توجه میکنند و سایر user agentها از دستورالعملهای موجود در گروه user-agent:* پیروی مینمایند.
مثالهایی از robots.txt
در اینجا چند نمونه از robots.txt برای سایت www.example.com آورده شده است:
آدرس فایل Robots.txt برای این سایت، www.example.com/robots.txt است.
1. مسدود کردن همه crawlerهای وب از کل محتوا
User-agent: * Disallow: /
استفاده از این ساختار در فایل robots.txt به همه crawlerهای وب میگوید که هیچ صفحهای را در www.example.com، از جمله صفحه اصلی، crawl نکنند.
2. صدور مجوز دسترسی به تمام محتواهای وب سایت برای تمام crawlerها
User-agent: * Disallow:
استفاده از این ساختار در فایل robots.txt به خزندههای وب میگوید که تمام صفحات www.example.com از جمله صفحه اصلی را میتوانند crawl کنند.
3. مسدود کردن یک crawler وب خاص از یک پوشه خاص
User-agent: Googlebot Disallow: /example-subfolder/
این ساختار تنها به خزنده Google (به نام Googlebot) میگوید که صفحاتی را که ابتدای URL آن www.example.com/example-subfolder/ است، crawl نکند.
4. مسدود کردن یک crawler وب خاص از یک صفحه وب خاص
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
این ساختار تنها به خزنده Bing (به نام Bing) میگوید که از crawl کردن صفحه www.example.com/example-subfolder/blocked-page.html اجتناب نماید.
robots.txt چگونه عمل میکند؟
موتورهای جستجو دو کار اصلی دارند:
1. خزیدن در وب برای کشف محتوا؛
2. فهرست سازی آن محتوا به گونهای که بتوان آن را برای جستجوگرانی که به دنبال اطلاعات هستند ارائه کرد.
برای خزیدن در سایتها، موتورهای جستجو لینکها را دنبال میکنند تا از یک سایت به سایت دیگر برسند. این رفتار خزیدن، گاهی اوقات به عنوان "spidering" نیز شناخته میشود.
crawler پس از رسیدن به یک وب سایت، قبل از spider کردن آن، به دنبال فایل robots.txt میگردد. اگر فایل را پیدا کرد، آن فایل را قبل از crawl کردن آن صفحه میخواند. از آنجایی که فایل robots.txt حاوی اطلاعاتی در مورد نحوه خزیدن موتور جستجو است، اطلاعاتی که در آنجا یافت میشود، اقدامات بعدی crawler را در این سایت خاص مشخص میکند. اگر فایل robots.txt حاوی دستورالعملهایی نباشد که فعالیت یک user-agent را ممنوع نماید (یا اگر آن سایت، فایل robots.txt را نداشته باشد)، به crawl کردن اطلاعات دیگر در سایت ادامه میدهد.
این مطلب نیز ممکن است برای شما مفید باشد: سئو (SEO) چیست؟
جزئیات بیشتر robots.txt
در ادامه، به جزئیات بیشتر فایل robots.txt پرداخته شده است:
فایل robots.txt باید در دایرکتوری سطح بالای وب سایت قرار گیرد تا crawler بتواند آن را بیابد.
Robots.txt به حروف کوچک و بزرگ حساس است: نام فایل باید به صورت "robots.txt" باشد (نه Robots.txt ،robots.TXT یا غیره)
برخی از user-agent (ربات)ها ممکن است فایل robots.txt شما را نادیده بگیرند. این امر به ویژه در مورد خزندههای بدجنس مانند روباتهای بدافزار یا خراش دهنده (scraper) آدرس ایمیل رایج است.
فایل /robots.txt به صورت عمومی در دسترس است: تنها کافیست /robots.txt را به انتهای هر دامنه اصلی اضافه نمایید تا دستورالعملهای آن وب سایت را ببینید (اگر آن سایت دارای فایل robots.txt باشد). این بدان معناست که هر کسی میتواند ببیند شما چه صفحاتی را میخواهید و چه صفحاتی را نمیخواهید crawl شود؛ بنابراین از آنها به منظور پنهان کردن اطلاعات خصوصی کاربر استفاده نکنید.
هر زیر دامنه در یک دامنه اصلی از فایلهای robots.txt جداگانه استفاده میکند. این بدان معناست که هم blog.example.com و هم example.com باید فایلهای robots.txt خود را (در blog.example.com/robots.txt و example.com/robots.txt) داشته باشند.
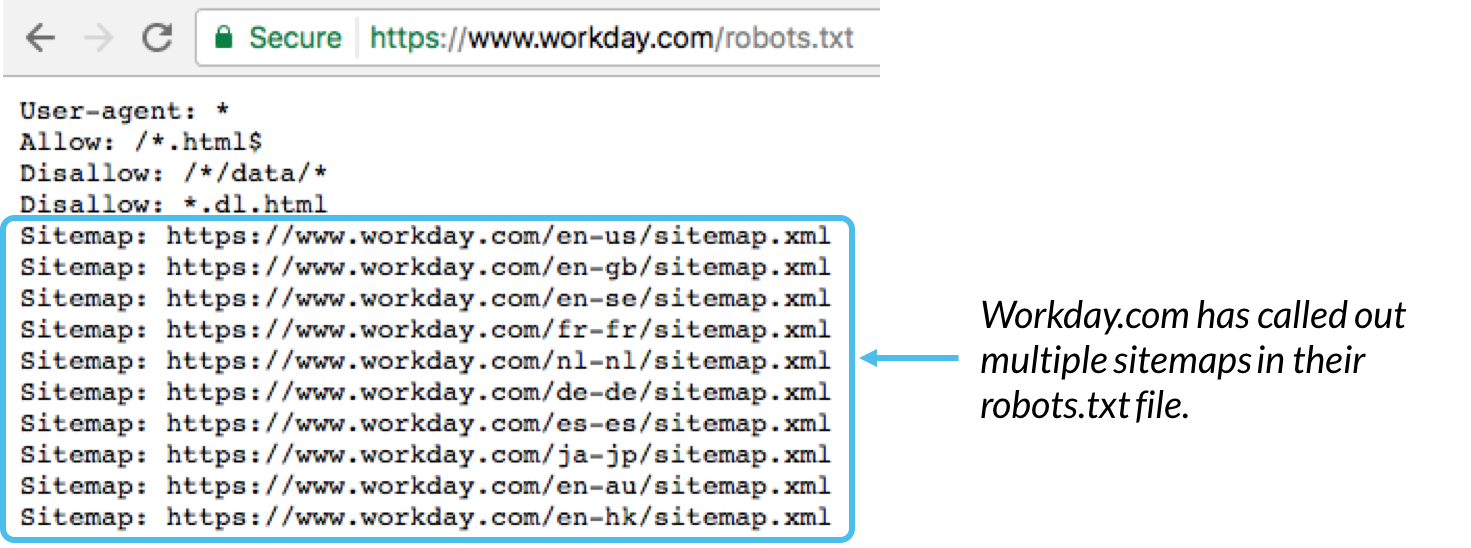
به طور کلی بهترین روش برای نشان دادن مکان هر sitemap مرتبط با این دامنه در پایین فایل robots.txt است. به عنوان مثال:
ساختار فنی robots.txt
ساختار Robots.txt را میتوان به عنوان "زبان" فایلهای robots.txt در نظر گرفت. پنج اصطلاح رایج وجود دارد که احتمالاً در فایل روباتها با آنها روبهرو خواهید شد. آنها عبارتند از:
User-agent: خزنده وب خاصی که دستورالعملهای خزیدن را به آن میدهید (معمولاً یک موتور جستجو). لیستی از بیشتر user agentها را میتوان در اینجا یافت.
Disallow: دستوری که به یک user-agent میگوید، URL خاصی را crawl نکند. تنها یک خط "Disallow:" برای هر URL مجاز است.
Allow (تنها برای Googlebot قابل اجرا است): دستوری که به Googlebot میگوید، میتواند به یک صفحه یا زیردایرکتوری دسترسی داشته باشد، حتی اگر صفحه یا زیردایرکتوری والد آن غیرمجاز باشد.
Crawl-Delay: یک crawler چند ثانیه باید قبل از بارگیری و خزیدن محتوای صفحه منتظر بماند. توجه داشته باشید که Googlebot این دستور را تایید نمیکند؛ اما نرخ خزیدن را میتوان در کنسول جستجوی گوگل تنظیم کرد.
Sitemap: برای فراخوانی sitemap(های) XML مرتبط با این URL استفاده میشود. توجه داشته باشید که این دستور فقط توسط ،Google ،Ask Bing و Yahoo پشتیبانی میشود.
تطبیق الگو
وقتی صحبت از URLهای واقعی برای مسدود کردن یا مجاز کردن به میان میآید، فایلهای robots.txt میتوانند نسبتاً پیچیده شوند؛ زیرا امکان استفاده از تطبیق الگو را برای پوشش طیف وسیعی از گزینههای URL ممکن ارائه میدهند. Google و Bing هر دو از دو regular expression استفاده میکنند که میتوانند برای شناسایی صفحات یا زیردایرکتوریهایی استفاده شوند که یک SEO میخواهد حذف شوند. این دو کاراکترها، ستاره (*) و علامت دلار ($) هستند.
*: یک علامت عام است که هر دنبالهای از کاراکترها را نشان میدهد.
$: با انتهای URL مطابقت دارد.
گوگل فهرستی عالی از ساختار و مثالهای ممکن تطابق الگو را در اینجا ارائه میکند.
مکان robots.txt در یک سایت
موتورهای جستجو و سایر روباتهای خزنده وب (مانند crawler فیسبوک، یعنی Facebot) هر زمان که به سایتی مراجعه میکنند، میدانند که باید ابتدا به دنبال فایل robots.txt بگردند. اما، آنها تنها در یک مکان مشخص به دنبال آن فایل میگردند: دایرکتوری اصلی (معمولاً دامنه اصلی یا صفحه اصلی شما). اگر یک user agent از www.example.com/robots.txt بازدید کند و فایل روباتی را در آنجا پیدا نکند، فرض میکند که آن سایت فایل robot.txt را ندارد و به crawl کردن در صفحه (و شاید حتی در کل سایت) ادامه میدهد. حتی اگر صفحه robots.txt مثلاً در example.com/index/robots.txt یا www.example.com/homepage/robots.txt وجود داشته باشد، توسط user agentها کشف نشده و در نتیجه سایت مورد بررسی قرار میگیرد. به گونهای که انگار اصلا فایل robots وجود نداشته است.
بنابراین، به منظور اطمینان از یافتن فایل robots.txt، همیشه آن را در دایرکتوری اصلی یا دامنه اصلی خود قرار دهید.
دلیل اهمیت robots.txt
فایلهای Robots.txt دسترسی crawler به مناطق خاصی از سایت شما را کنترل میکنند. در حالی که اگر شما به طور تصادفی Googlebot را از خزیدن در کل سایت خود (!!) منع نمایید، میتواند بسیار خطرناک باشد. به همین دلیل وجود فایل robots.txt میتواند بسیار مفید باشد.
برخی از موارد استفاده عبارتند از:
- جلوگیری از ظاهر شدن محتوای تکراری در SERP (توجه داشته باشید که متا روباتها اغلب انتخاب بهتری برای این کار هستند)
- خصوصی نگه داشتن بخشهای کامل یک وب سایت (به عنوان مثال، سایت مرحله بندی تیم مهندسی شما)
- جلوگیری از نمایش صفحات نتایج جستجوی داخلی در یک SERP عمومی
- تعیین مکان sitemap(ها)
- جلوگیری از فهرست بندی فایلهای خاص در وب سایت شما (تصاویر، PDF و غیره) توسط موتورهای جستجو.
- تعیین تأخیر خزیدن به منظور جلوگیری از بارگیری بیش از حد سرورهای شما هنگام بارگیری همزمان چندین قطعه محتوا توسط خزندهها
اگر هیچ ناحیهای در سایت شما وجود ندارد که بخواهید دسترسی user agent را برروی آن کنترل کنید، ممکن است اصلاً به فایل robots.txt نیاز نداشته باشید.
بررسی اینکه آیا فایل robots.txt را دارید یا خیر
آیا از وجود فایل robots.txt مطمئن نیستید؟ کافیست دامنه اصلی خود را تایپ کنید، سپس /robots.txt را به انتهای URL اضافه نمایید. در صورتی که هیچ صفحه .txt نمایش داده نشد، در حال حاضر هیچ صفحه robots.txt (بصورت زنده) ندارید.
ایجاد فایل robots.txt
اگر مطمئن شدید که فایل robots.txt را ندارید؛ یا میخواهید فایل خود را تغییر دهید، ایجاد آن یک فرآیند ساده است. این مقاله از Google فرآیند ایجاد فایل robots.txt را طی میکند و این ابزار به شما امکان میدهد، درستی پیکربندی فایل خود را تست کنید.
بهترین شیوههای سئو
اطمینان حاصل کنید که هیچ محتوا یا بخشی از وب سایت خود را که میخواهید crawl شود، مسدود نکرداید.
پیوندهای موجود در صفحات مسدود شده توسط robots.txt دنبال نمیشوند. بنابراین در صورتی که میخواهید آن لینکها crawl شوند باید از دیگر صفحات قابل دسترسی موتور جستجو (به عنوان مثال صفحاتی که از طریق robots.txt، رباتهای متا یا موارد دیگر مسدود نشدهاند) پیوند داده شده باشند. چراکه منابع پیوند داده شده crawl نمیشوند و حتی ممکن است فهرست بندی نشوند.
دقت کنید که هیچ ارزش پیوندی (link equity) را نمیتوان از صفحه مسدود شده به مقصد پیوند منتقل کرد. اگر صفحاتی دارید که میخواهید ارزش آنها منتقل شود، از مکانیسم مسدودسازی دیگری غیر از robots.txt استفاده نمایید.
از robots.txt به منظور جلوگیری از نمایش دادههای حساس (مانند اطلاعات خصوصی کاربر) در نتایج SERP استفاده نکنید. از آنجایی که صفحات دیگر ممکن است مستقیماً به صفحه حاوی اطلاعات خصوصی پیوند داشته باشند؛ در نتیجه دستورالعملهای robots.txt در دامنه اصلی یا صفحه اصلی شما دور زده شده و ممکن است همچنان فهرست بندی شود. اگر میخواهید صفحه خود را از نتایج جستجو مسدود نمایید، از روش دیگری مانند محافظت با رمز عبور یا دستورالعمل noindex meta استفاده کنید.
برخی از موتورهای جستجو دارای چندین user agent هستند. به عنوان مثال، Google از Googlebot برای جستجوی ارگانیک و از Googlebot-Image برای جستجوی تصویر استفاده میکند. اکثر user agentها با یک موتور جستجو از قوانین یکسانی پیروی میکنند؛ بنابراین نیازی به تعیین دستورالعمل برای هر یک از crawlerهای موتور جستجو نیست؛ اما داشتن توانایی انجام این کار به شما این امکان را میدهد که نحوه crawl کردن محتوای سایت خود را دقیق مشخص نمایید.
یک موتور جستجو محتویات robots.txt را در کش ذخیره میکند؛ اما معمولاً حداقل یک بار در روز مطالب ذخیره شده را به روز مینماید. اگر فایل را تغییر میدهید و میخواهید آن را سریعتر از معمول بهروزرسانی کنید، میتوانید نشانی اینترنتی robots.txt خود را به Google ارسال نمایید.
Robots.txt در مقابل meta robot در مقابل x-robot
تفاوت بین این سه نوع دستورالعمل ربات چیست؟ اول از همه، robots.txt یک فایل متنی واقعی است؛ در حالی که mata robot و x-robot دستورات متا هستند. فراتر از آنچه در واقع هستند، هر سه عملکردهای متفاوتی دارند. Robots.txt رفتار خزیدن در سراسر سایت یا دایرکتوری را اجرا میکند؛ در حالی که meta robot و x-robot میتوانند رفتار فهرست سازی را در سطح یک صفحه (یا عنصر صفحه) اجرا نمایند.
منبع:
moz
 کوچک نگه داشتن سایز Docker Image
کوچک نگه داشتن سایز Docker Image  گواهی SSL چیست؟
گواهی SSL چیست؟  RAID (آرایه چندگانه دیسکهای مستقل)
RAID (آرایه چندگانه دیسکهای مستقل)  نصب و پیکربندی OpenLiteSpeed با PHP 7 در CentOS 7
نصب و پیکربندی OpenLiteSpeed با PHP 7 در CentOS 7
0 دیدگاه
نوشتن دیدگاه