
Hadoop یک چارچوب نرمافزاری رایگان، منبع باز و مبتنی بر جاوا است که برای ذخیرهسازی و پردازش مجموعهای بزرگ از دادهها برروی چندین دستگاه (خوشه هایی از سرورها) استفاده میشود. این برنامه، از HDFS ( سیستم فایل توزیع شده Hadoop) برای ذخیره دادههای خود و پردازش این دادهها با استفاده از MapReduce استفاده میکند. این نرم افزار، یک اکوسیستم از ابزارهای Big Data است که توسط کمپانی Apache ساخته شده است و در درجه اول برای داده کاوی و یادگیری ماشین مورد استفاده قرار میگیرد. Hadoop معمولاً پردازش ها را به صورت توزیع شده (بر روی چند کامپیوتر مختلف) انجام داده و نتایج را به کامپیوتر مقصد برمیگرداند.
Hadoop شامل چهار جزء اصلی Hadoop Common ،HDFS ،YARN و MapReduce میباشد. استفادهکنندگان برجسته Hadoop، فیسبوک و یاهو هستند.
در این راهنما، نحوه نصب Apache Hadoop را بر روی RHEL/CentOS 8 توضیح خواهیم داد.
مرحله 1: غیرفعال سازی SELinux
قبل از شروع، بهتر است SELinux را در سیستم خود غیرفعال کنید.
برای غیرفعال کردن SELinux، فایل etc/selinux/config/ را باز کنید:
$ nano /etc/selinux/config
سپس خط زیر را تغییر دهید:
SELINUX=disabled
فایل را پس از اتمام کار، ذخیره کرده و سیستم خود را مجدداً راهاندازی نمایید تا تغییرات SELinux اعمال شود.
مرحله 2: نصب جاوا
Hadoop به زبان جاوا نوشته شده است و فقط از نسخه 8 جاوا پشتیبانی میکند. شما میتوانید OpenJDK 8 و ant را با استفاده از دستور DNF بصورت شکل زیر نصب نمایید:
$ dnf install java-1.8.0-openjdk ant -y
پس از نصب، نسخه نصب شده جاوا را با دستور زیر تأیید کنید:
$ java -version
اکنون باید خروجی زیر را بدست آورید:
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
مرحله 3: ایجاد یک کاربر Hadoop
بهتر است یک کاربر جداگانه بهمنظور اجرای Hadoop بهدلایل امنیتی ایجاد نمایید.
دستور زیر را برای ایجاد یک کاربر جدید با نام hadoop اجرا کنید:
$ useradd hadoop
در مرحله بعد، رمزعبور را برای این کاربر با دستور زیر تنظیم نمایید:
$ passwd hadoop
بصورت زیر، رمز جدید را ارائه و تأیید کنید:
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
مرحله 4: پیکربندی احراز هویت مبتنی بر کلید SSH
در این مرحله، باید تأیید هویت SSH بدون پسورد را برای سیستم محلی پیکربندی نمایید.
بدین منظور، ابتدا با دستور زیر، کاربر را به hadoop تغییر دهید:
$ su - hadoop
سپس، برای تولید جفتهای کلید عمومی و خصوصی، دستور زیر را اجرا کنید:
$ ssh-keygen -t rsa
در اینجا، از شما خواسته میشود نام فایل را وارد نمایید. برای تکمیل مراحل، فقط Enter را فشار دهید:
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:a/og+N3cNBssyE1ulKK95gys0POOC0dvj+Yh1dfZpf8 hadoop@centos8
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| . |
| . o o o |
| . . o S o o |
| o = + O o . |
|o * O = B = . |
| + O.O.O + + . |
| +=*oB.+ o E|
+----[SHA256]-----+
در مرحله بعد، کلیدهای عمومی تولید شده را از id_rsa.pub به authorized_keys اضافه کرده و مجوز مناسب را تنظیم نمایید:
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 640 ~/.ssh/authorized_keys
سپس، تأیید هویت SSH بدون پسورد را با دستور زیر بررسی کنید:
$ ssh localhost
در اینجا، از شما خواسته میشود با اضافه کردن کلیدهای RSA به فایل میزبانهای شناخته شده، میزبانها را تأیید نمایید. در اینجا، yes را تایپ کنید و برای تأیید اعتبار میزبان محلی، Enter را بزنید:
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:0YR1kDGu44AKg43PHn2gEnUzSvRjBBPjAT3Bwrdr3mw.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Sat Feb 1 02:48:55 2020
[hadoop@centos8 ~]$

مرحله 5: نصب Hadoop
ابتدا با دستور زیر، کاربر را به hadoop تغییر دهید:
$ su - hadoop
سپس، آخرین نسخه Hadoop را با استفاده از دستور wget دانلود کنید:
$ wget http://apachemirror.wuchna.com/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
پس از دانلود، فایل دانلود شده را استخراج نمایید:
$ tar -xvzf hadoop-3.2.1.tar.gz
سپس، دایرکتوری استخراج شده را به hadoop تغییر نام دهید:
$ mv hadoop-3.2.1 hadoop
در مرحله بعد، شما باید Hadoop و متغیرهای محیطی جاوا را روی سیستم خود پیکربندی کنید.
بدین منظور، فایل bashrc./~ را در یک ویرایشگر باز نمایید:
$ nano ~/.bashrc
خطوط زیر را اضافه کنید:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
فایل را ذخیره کرده و ببندید. سپس متغیرهای محیطی را با دستور زیر فعال نمایید:
$ source ~/.bashrc
پس از آن، فایل متغیر محیطی Hadoop را باز کنید:
$ nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
متغیر JAVA_HOME را طبق مسیر نصب جاوای سیستم خود به روز نمایید:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/
پس از اتمام، فایل را ذخیره کرده و ببندید.
مرحله 6: پیکربندی Hadoop
ابتدا، شما باید دایرکتوریهای namenode و datanode را در دایرکتوری اصلی Hadoop ایجاد نمایید:
دستور زیر را برای ایجاد هر دو دایرکتوری اجرا کنید:
$ mkdir -p ~/hadoopdata/hdfs/namenode
$ mkdir -p ~/hadoopdata/hdfs/datanode
سپس، فایل core-site.xml را ویرایش کرده و نام میزبان سیستم خود را به روز نمایید:
$ nano $HADOOP_HOME/etc/hadoop/core-site.xml
نام زیر را مطابق نام میزبان سیستم خود تغییر دهید:
fs.defaultFS
hdfs://hadoop.tecadmin.com:9000
فایل را ذخیره کرده و ببندید. سپس فایل hdfs-site.xml را ویرایش نمایید:
$ nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
مسیر دایرکتوری NameNode و DataNode را مطابق شکل زیر تغییر دهید:
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hadoopdata/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hadoopdata/hdfs/datanode
فایل را ذخیره کرده و ببندید. سپس، فایل mapred-site.xml را ویرایش نمایید:
$ nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
تغییرات زیر را انجام دهید:
mapreduce.framework.name
yarn
فایل را ذخیره کرده و ببندید. سپس فایل yarn-site.xml را ویرایش نمایید:
$ nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
تغییرات زیر را انجام دهید:
yarn.nodemanager.aux-services
mapreduce_shuffle
پس از اتمام کار، فایل را ذخیره کرده و ببندید.
مرحله 7: آغاز خوشهبندی Hadoop
قبل از شروع خوشهبندی Hadoop، شما باید Namenode را بهعنوان کاربر hadoop قالببندی کنید.
دستور زیر را برای قالببندی hadoop Namenode اجرا نمایید:
$ hdfs namenode -format
شما باید خروجی زیر را بدست آورید:
2020-02-05 03:10:40,380 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-02-05 03:10:40,389 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-02-05 03:10:40,389 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.com/45.58.38.202
************************************************************/
پس از قالببندی Namenode، دستور زیر را اجرا کنید تا خوشهبندی hadoop شروع شود:
$ start-dfs.sh
پس از شروع موفقیتآمیز HDFS، باید خروجی زیر را بدست آورید:
Starting namenodes on [hadoop.tecadmin.com]
hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [hadoop.tecadmin.com]
سپس، سرویس YARN را بصورت زیر راهاندازی نمایید:
$ start-yarn.sh
شما باید خروجی زیر را بدست آورید:
Starting resourcemanager
Starting nodemanagers
اکنون میتوانید با استفاده از دستور jps، وضعیت کلیه سرویسهای Hadoop را بررسی کنید:
$ jps
شما باید تمام سرویسهای در حال اجرا را در خروجی زیر مشاهده نمایید:
7987 DataNode
9606 Jps
8183 SecondaryNameNode
8570 NodeManager
8445 ResourceManager
7870 NameNode
این مطلب نیز ممکن است برای شما مفید باشد: افزودن آدرس IP در فایروال ویندوز
مرحله 8: پیکربندی فایروال
Hadoop، اکنون برروی پورت 9870 و 8088 شروع به کار کرده و در حال شنود است. در مرحله بعد، باید این پورتها را از طریق فایروال باز کنید.
دستور زیر را اجرا نمایید تا اتصالات Hadoop از طریق فایروال امکانپذیر باشد:
$ firewall-cmd --permanent --add-port=9870/tcp
$ firewall-cmd --permanent --add-port=8088/tcp
سپس، سرویس Firewalld را مجدداً بارگیری نمایید تا تغییرات اعمال شود:
$ firewall-cmd --reload
مرحله 9: دسترسی به Hadoop Namenode و مدیریت منابع
برای دسترسی به Namenode، مرورگر وب خود را باز کرده و آدرس http://your-server-ip:9870 را وارد نمایید. صفحه زیر را باید مشاهده کنید:
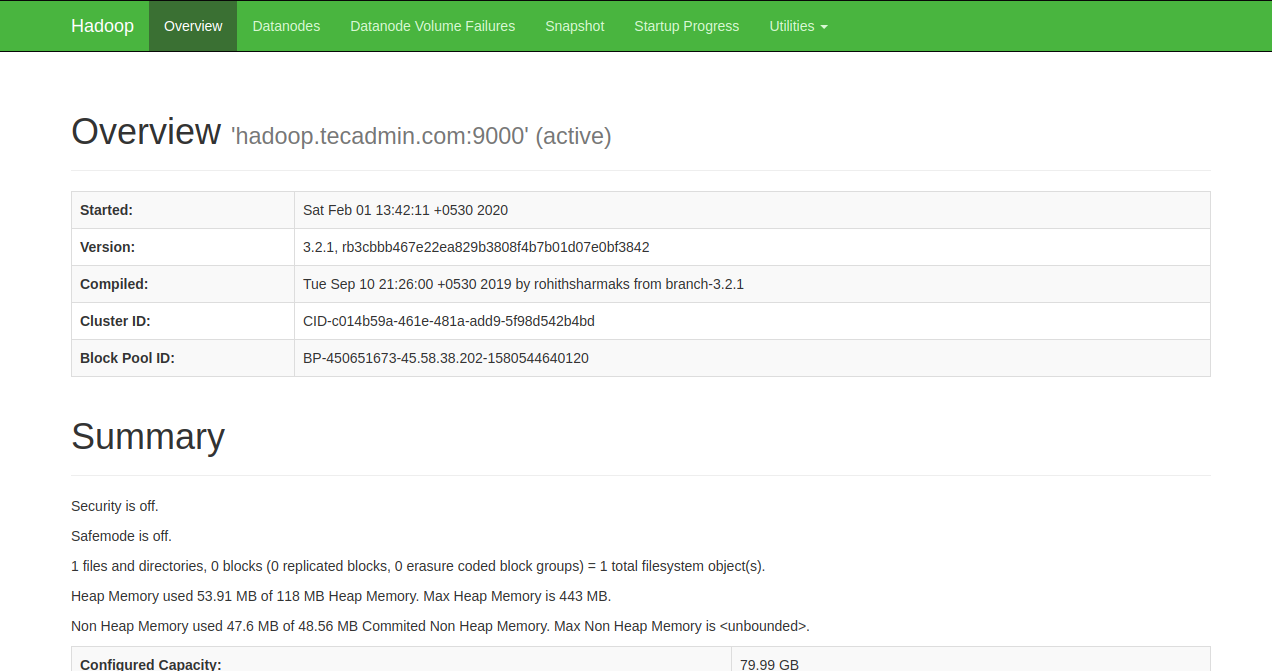
برای دسترسی به مدیریت منابع، مرورگر وب خود را باز کرده و آدرس http://your-server-ip:8088 را وارد نمایید. صفحه زیر را باید مشاهده کنید:
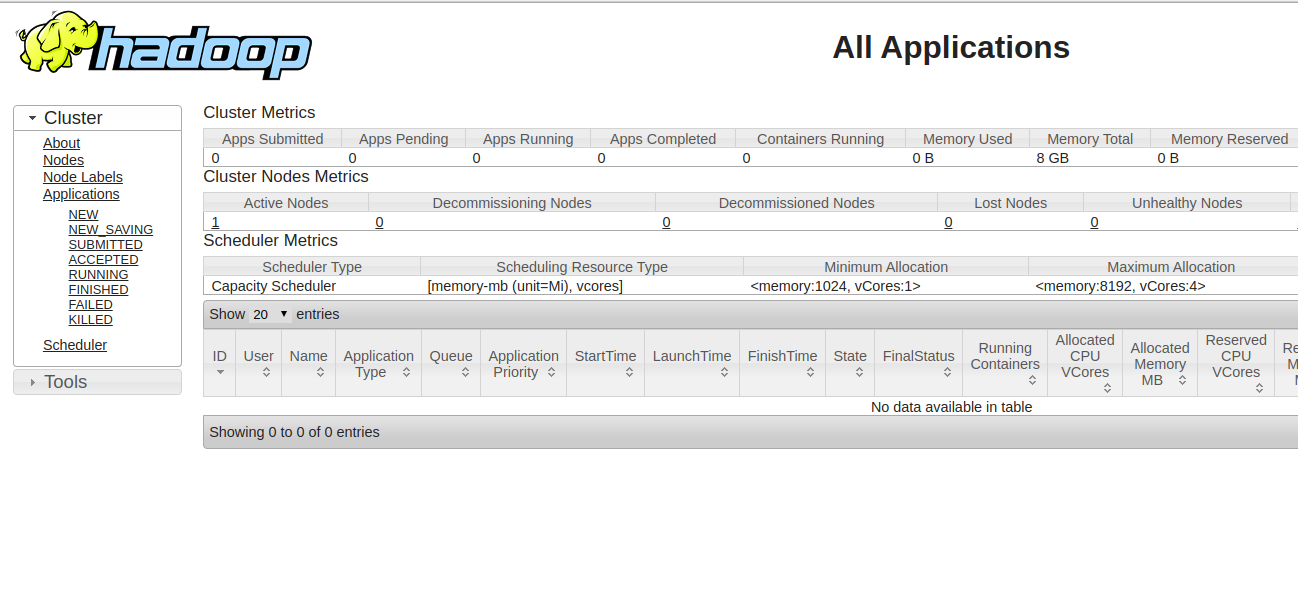
مرحله 10: بررسی بسته بندی Hadoop
تا اینجا، خوشهبندی Hadoop نصب و پیکربندی شده است. سپس، برخی از دایرکتوریها را در سیستم فایل HDFS برای تست Hadoop ایجاد خواهیم کرد.
برای ایجاد دایرکتوریها در سیستم فایل HDFS، دستور زیر را وارد نمایید:
$ hdfs dfs -mkdir /test1
$ hdfs dfs -mkdir /test2
پس از آن، دستور زیر را برای نمایش دایرکتوری بالا اجرا کنید:
$ hdfs dfs -ls /
شما باید خروجی زیر را بدست آورید:
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2020-02-05 03:25 /test1
drwxr-xr-x - hadoop supergroup 0 2020-02-05 03:35 /test2
همچنین میتوانید دایرکتوری بالا را در رابط وب Hadoop Namenode نیز تأیید نمایید.
بدین منظور، به رابط وب Namenode بروید، برروی گزینه Utilities و سپس Browse the file system کلیک کنید. شما باید دایرکتوریهای خود را که اکنون ایجاد کردهاید، در صفحه زیر مشاهده کنید:
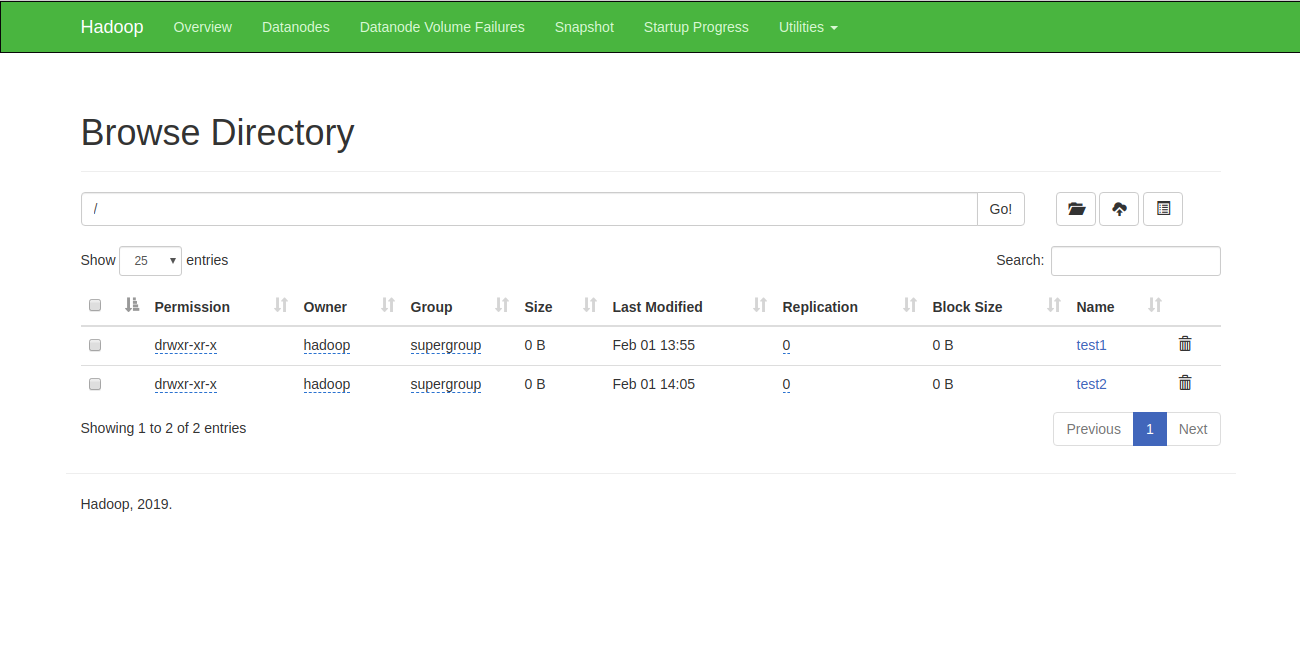
مرحله 11: متوقف کردن خوشهبندی Hadoop
شما میتوانید با اجرای اسکریپت stop-dfs.sh و stop-yarn.sh بهعنوان یک کاربر Hadoop نیز، سرویس Hadoop Namenode و Yarn را هر زمان که بخواهید متوقف نمایید.
برای متوقف کردن سرویس Hadoop Namenode، دستور زیر را بهعنوان یک کاربر hadoop اجرا کنید:
$ stop-dfs.sh
برای متوقف کردن سرویس Manager Hadoop، دستور زیر را اجرا نمایید:
$ stop-yarn.sh
منبع:
 تغییر نام کاربری در DirectAdmin
تغییر نام کاربری در DirectAdmin  مزیت استفاده از Multi Stage Build در داکر
مزیت استفاده از Multi Stage Build در داکر  مدیریت Directory listing با htaccess
مدیریت Directory listing با htaccess  راهنمای سیستم فایل 'proc/' در لینوکس
راهنمای سیستم فایل 'proc/' در لینوکس
0 دیدگاه
نوشتن دیدگاه